
0) Sequential Model
Sequential data를 다루는데 어려운 점
-> 길이가 언제 끝날지 모른다. 즉 입력의 차원을 미리 알 수 없다. 따라서 앞서 보았던 fully connected layer나 convolution layer를 사용하지 못한다.
런 Sequential data을 다루기 위해 Sequential Model을 고안한다.
Naive한 Sequential Model

data가 늘어날수록 고려해야할 과거의 정보가 많아진다.
Autoregressive model

위에서는 모든 과거의 data를 적용하기에 이 모델은 참고해야할 과거의 숫자를 고정한다.
Markov model(first-order autoregressive model)

마르코프 모델은 마르코프 특성을 따른다.
마르코프 특성이란??
나의 현재상태가 바로 이전의 과거에만 의존적이라는 가정이다.
바로 이전과거에만 의존하기에 그 이전의 많은 정보는 버리게 된다.
Latent autoregressive model

Autoregressive model의 정보는 과거의 많은 정보를 고려한다는 것이 불가능 하다는 것이다.
따라서 Latent autoregressive model은 hidden state를 추가하여 과거의 정보를 요약할 수 있게 했다. 다음 번의 입력에서는 hidden state 1개에 의존하게 된다.
1) Recurrent Neural Networks

위의 개념들이 포함되어 있는 Recurrent Neural network이다. MLP와 비슷하지만 다른 점은 자기 자신에게 돌아오는 화살표가 있다는 것이다. 이것은 이전상태가 새로운 입력을 받았을 때 고려된다는 것을 의미한다.

이 그림은 위의 RNN을 시간 순서대로 풀어 표현한 것이다. 이렇게 풀면 RNN은 굉장히 많은 fully connected layer로 표현 된다는 것을 알게 된다.
그러나 이런 Vanilla RNN에는 큰 단점이 있다.
Short-term dependecis라는 문제이다. 바로 오래된 과거의 정보는 살아남기 힘들다는 것이다. 살아남기 힘든 이유는 RNN의 계산과정을 보면 알 수 있다

RNN의 수식을 풀어 쓰면 Weight 값을 곱하는 과정이 굉장히 많음을 알 수 있다. 만약 weight 값이 0과 1사이에 있다면 곱하는 과정에서 점점 작아져 기울기가 소실 되는 vanishing gradient 문제가 나타난다.
반대로 1보다 weight 값이 크다면 곱하며 기울기가 과도 하게 커져 폭발하는 exploding gradient 문제가 나타나게 된다.
따라서 이러한 Vanilla RNN의 단점을 보완하기 위해 나온 개념이 바로 LSTM, GRU 같은 RNN 구조이다.
2) LSTM(Long Short Term Memory)

기존 Vanilla RNN의 구조는 Input과 hidden state 만 존재하는 구조였다. LSTM은 여기에 cell state라는 것이 추가 된다.
cell state는 과거의 정보와 현재의 정보를 적절히 섞어준다. -> Long Term memory
어떻게?? 내부의 network들이 데이터 학습을 통해 적절한 비율을 알아간다. 기존에는 무조건 t-1이 반영이 되었는데 무조건반영되는 것이 아니라 잊혀질지 반영할지를 반영한다.




gate 얼마나 비율로 잊을지, 얼마나 비율로 반영할지를 정해줌. 여기서 sigmoid 함수는 얼마나 반영할지에 대한 수치를 구하기 위한 활성화 함수로 해석 할 수 있다. 그리고 tanh 함수는 확률이 아닌 정보 자체를 나타내며 이를 통해 gradient를 최대한 오래 유지하게 해 vanishing gradient 문제를 해결히는데 도움을 준다.
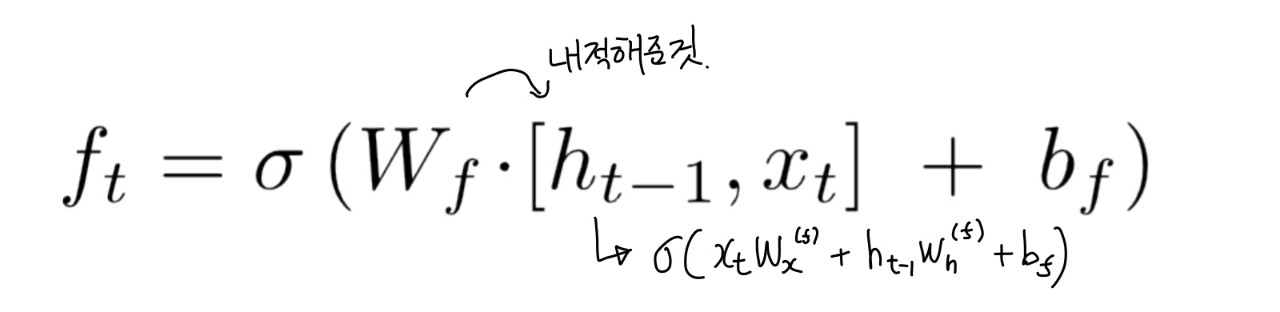



gate는 3개의 gate가 있다. forget gate, input gate, output gate이다. 3개의 gate들의 공통점은 다 hidden state(저번에 받은 input 의 정보)와 input x의 affine을 사용한다는 것이다.
그래서 내가 정리한 내용은 이렇다.
cell state -> Long term memory로 더 과거의 정보들의 상태를 나타낸다. 그리고 이는 과거의 정보를 얼마나 잊을지, 현재의 정보는 얼마나 반영할지가 나타내어져 있다. cell state는 현재 입력과 이전 상태의 정보를 이용하여 정보를 저장하고 전달하기 위한 값
hidden state -> hidden state는 현재 입력과 이전 상태의 정보를 모두 포함하고 있는 출력값
input -> 현재 들어온 input 값을 말한다.
3) GRU(Gated Recurrent Unit)

LSTM보다 성능이 좋다고 알려져있지만 요즘에는 transformer 모델로 거의 대체되는 추세이다.
GRU는 LSTM과 달리 reset gate와 update gate, 2개의 gate로 구성되어있다.
또 GRU는 cell state가 존재하지 낳고 hidden state만 존재하게 된다.
공부하며 이해가 안될 때 보았던 유튜브 링크들이다.
'AI > Deep Learning' 카테고리의 다른 글
| Generative Model (Autoregressive model) (0) | 2023.03.24 |
|---|---|
| Optimizer (0) | 2023.03.24 |
| Transformer (0) | 2023.03.23 |
| Neural Network & MLP(Multi Layer Perceptron) (0) | 2023.03.20 |
| 0. Deep Learning 개요 (0) | 2023.03.20 |