
-
0) Gradient Descent(경사 하강법)
-
-
-
1) Optimization에서의 중요한 개념
-
1. Generalization
-
2. Underfitting, Overfitting
-
3. Cross Validation(K - fold validation)
-
4. Bias-variance tradeoff
-
5. Bootstrapping
-
6. Bagging and boosting
-
2) Gradient Descent Methods
-
전통적인 Descent Methods
-
이제 다른 optimizer에 대해 알아보자.
-
3) Regularization
0) Gradient Descent(경사 하강법)
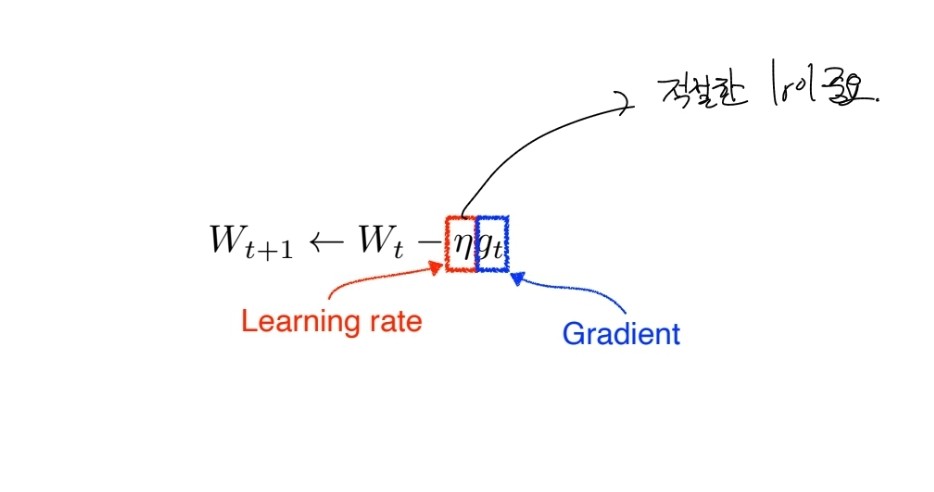
Gradient Descent(경사 하강법)은 머신 러닝에서 모델을 학습시키는 최적화 알고리즘 중 하나입니다. Gradient Descent는 함수의 기울기(gradient)를 이용하여 함수의 최솟값을 찾아가는 방법입니다.
Gradient Descent의 개념은 다음과 같습니다. 먼저, 모델의 손실 함수(loss function)를 정의합니다. 손실 함수는 모델의 예측 값과 실제 값의 차이를 측정하는 함수입니다. Gradient Descent는 이 손실 함수의 기울기를 이용하여 최적의 모델 파라미터를 찾아갑니다.
Gradient Descent는 먼저 임의의 초기값을 가지고 시작합니다. 이후, 현재 위치에서 손실 함수의 기울기를 계산하고, 기울기가 가리키는 방향으로 일정 거리만큼 이동합니다. 이를 여러 번 반복하여 손실 함수의 값이 최소값에 수렴할 때까지 찾아가는 것입니다.
1) Optimization에서의 중요한 개념
1. Generalization
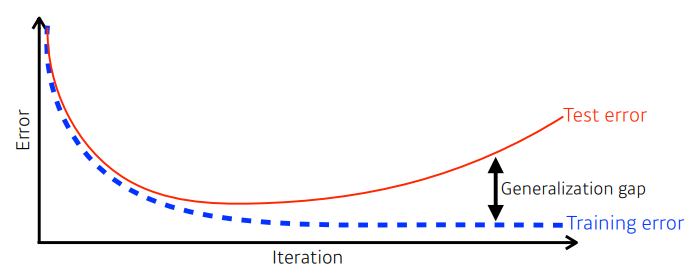
- train error와 test error 사이의 차이를 말한다.
- Generalization이 좋다는 것은 이 둘의 차이가 적다는 것을 말한다.
2. Underfitting, Overfitting
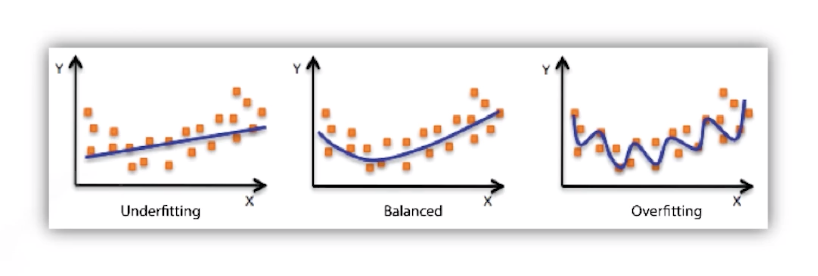
- Underfitting: 학습이 덜 된 상태를 말한다.
- Overfitting: 과하게 학습이 된 상태를 말한다.
3. Cross Validation(K - fold validation)

학습 data를 나눈다. k 개로 나눠서 k-1개는 학습 set으로 사용하고 1개는 test로 성능을 측정하는 것이 Cross validation이다. 조금 헷갈렸던 것이 내가 생각한 test data가 사실은 validation data였다는 것이다. test data를 모델에 사용하는 것은 cheating 이라고 한다. 따라서 모델에서 사용하는 테스트 데이터, 즉 검증 데이터는 train data에서 나누어서 사용한다.
4. Bias-variance tradeoff

편향과 분산이다. 편향은 과녁 중앙에서 벗어나 있느 정도를 말하고 분산은 기준점에서 얼마나 흩어져 있나를 말한다.

분산과 편향은 서로 Tradeoff 인 관계에 있다. 즉 두가지 다 좋게 만들 수 없고 편향이 좋다면 분산값이 낮아질 수 있고 분산 값이 높다면 편향이 나빠질 수 있다.
5. Bootstrapping
부트스트래핑(bootstrapping)은 통계학에서 사용되는 샘플링 방법으로, 작은 샘플 데이터를 이용하여 모집단의 특성을 추정하는 방법입니다.
일반적으로, 통계학에서는 큰 모집단으로부터 추출된 샘플 데이터를 이용하여 모집단의 특성을 추정합니다. 그러나 부트스트래핑은 이러한 방법과는 다르게, 작은 샘플 데이터를 이용하여 모집단의 특성을 추정하는 방법입니다.
- 100개의 data가 있다면 80개로 여러 모델을 만들어서 무언가를 하겠다는 말이다.
6. Bagging and boosting
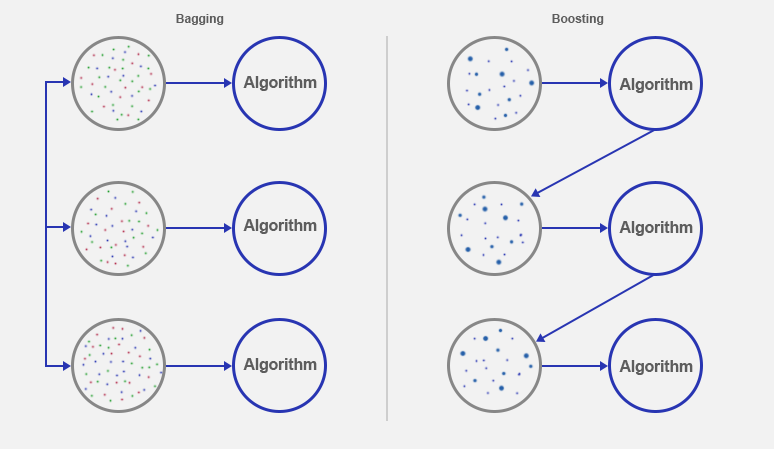
- Bagging (Bootstrapping aggregating)
배깅은 Bootstrap Aggregating의 줄임말로, 중복을 허용하는 샘플링을 이용하여 여러 개의 분류기를 학습시키고, 그 결과를 투표(voting)하여 가장 많은 표를 얻은 결과를 최종적인 예측 결과로 선택하는 방식입니다. 각 분류기들은 서로 독립적으로 학습되며, 개별 분류기의 오차는 전체 모델의 오차를 감소시키는 데 기여합니다. 대표적인 예로는 랜덤 포레스트(Random Forest)가 있습니다.
bootstrapping 을 이용해 무언 갈 하는 것을 말한다.
- boosting
100개중 80개를 맞추는 모델이 있다면 나머지 20개의 잘 안되는 data의 모델(weak learner)을 만들고 연결시켜 하나의 큰 strong learner로 만드는 것을 말한다.
2) Gradient Descent Methods
전통적인 Descent Methods
- SGD(stochastic gradient descent)
- 엄밀히 말하면 10만개 data가 있다면 그중 1개를 뽑아 gradient를 update하는 것을 말한다.
- mini-batch gradient descent
- 10만개의 data가 있다면 그 중 batch size 만큼 sample을 뽑아 gradient를 update한다.
- batch gradient descent
- 10만개 data를 한 꺼번에 이용하여 gradient를 update한다.

batch size를 작게하는 것이 좋다는 것이 알려져 있다. batch size 가 작다면 flat minimizers가 되는데, 그러면 test data와 train data 의 loss 차이가 별로 나지 않게 된다.
하지만 batch -size를 크게 하면 sharp minimizers가 되는데 이 때 training function이 극소점에 있으면 testing Function은 loss값이 높은 것을 볼 수 있다.
이제 다른 optimizer에 대해 알아보자.
1. SGD
2. Momentum

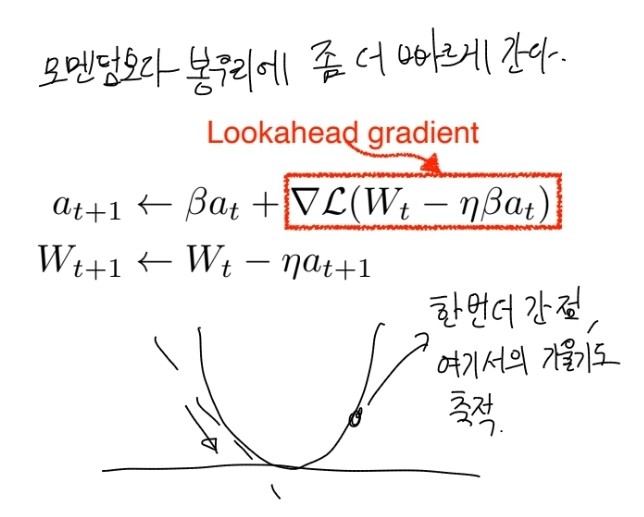
3. Nsterov Accelerated Gradient
4. Adagrad

5. Adadelta

6. RMSprop

7. Adam

3) Regularization
언젠가 pytorch 커뮤니티에서 우스갯소리로 지도학습이 아니라 '강제학습'이라고 하는 이야기를 들은 것 같다. 이는 너무 학습 data에 치우치게 학습해 일반적인 test data에 적용이 안되는 현상을 농담처럼 말한 것 같다. 따라서 Regularization은 과도한 학습을 막기 위해 학습을 방해하는 규제를 하는 방법이다.
1. Early stopping

말 그대로 일찍 training을 멈추는 방법이다.
2. Parameter norm penalty

3. Data augmentation

data를 지지고 볶아서 더 만들어내는 것
4. Noise robustness

5. Label smoothing
mix up
cut mix

6. Drop out

7. Batch normalization

'AI > Deep Learning' 카테고리의 다른 글
| Generative Model 2(VAE, GAN, Diffusion) (0) | 2023.03.26 |
|---|---|
| Generative Model (Autoregressive model) (0) | 2023.03.24 |
| Transformer (0) | 2023.03.23 |
| RNN(Recurrent Neural Networks) (0) | 2023.03.22 |
| Neural Network & MLP(Multi Layer Perceptron) (0) | 2023.03.20 |
0) Gradient Descent(경사 하강법)
Gradient Descent(경사 하강법)은 머신 러닝에서 모델을 학습시키는 최적화 알고리즘 중 하나입니다. Gradient Descent는 함수의 기울기(gradient)를 이용하여 함수의 최솟값을 찾아가는 방법입니다.
Gradient Descent의 개념은 다음과 같습니다. 먼저, 모델의 손실 함수(loss function)를 정의합니다. 손실 함수는 모델의 예측 값과 실제 값의 차이를 측정하는 함수입니다. Gradient Descent는 이 손실 함수의 기울기를 이용하여 최적의 모델 파라미터를 찾아갑니다.
Gradient Descent는 먼저 임의의 초기값을 가지고 시작합니다. 이후, 현재 위치에서 손실 함수의 기울기를 계산하고, 기울기가 가리키는 방향으로 일정 거리만큼 이동합니다. 이를 여러 번 반복하여 손실 함수의 값이 최소값에 수렴할 때까지 찾아가는 것입니다.
1) Optimization에서의 중요한 개념
1. Generalization
- train error와 test error 사이의 차이를 말한다.
- Generalization이 좋다는 것은 이 둘의 차이가 적다는 것을 말한다.
2. Underfitting, Overfitting
- Underfitting: 학습이 덜 된 상태를 말한다.
- Overfitting: 과하게 학습이 된 상태를 말한다.
3. Cross Validation(K - fold validation)
학습 data를 나눈다. k 개로 나눠서 k-1개는 학습 set으로 사용하고 1개는 test로 성능을 측정하는 것이 Cross validation이다. 조금 헷갈렸던 것이 내가 생각한 test data가 사실은 validation data였다는 것이다. test data를 모델에 사용하는 것은 cheating 이라고 한다. 따라서 모델에서 사용하는 테스트 데이터, 즉 검증 데이터는 train data에서 나누어서 사용한다.
4. Bias-variance tradeoff
편향과 분산이다. 편향은 과녁 중앙에서 벗어나 있느 정도를 말하고 분산은 기준점에서 얼마나 흩어져 있나를 말한다.
분산과 편향은 서로 Tradeoff 인 관계에 있다. 즉 두가지 다 좋게 만들 수 없고 편향이 좋다면 분산값이 낮아질 수 있고 분산 값이 높다면 편향이 나빠질 수 있다.
5. Bootstrapping
부트스트래핑(bootstrapping)은 통계학에서 사용되는 샘플링 방법으로, 작은 샘플 데이터를 이용하여 모집단의 특성을 추정하는 방법입니다.
일반적으로, 통계학에서는 큰 모집단으로부터 추출된 샘플 데이터를 이용하여 모집단의 특성을 추정합니다. 그러나 부트스트래핑은 이러한 방법과는 다르게, 작은 샘플 데이터를 이용하여 모집단의 특성을 추정하는 방법입니다.
- 100개의 data가 있다면 80개로 여러 모델을 만들어서 무언가를 하겠다는 말이다.
6. Bagging and boosting
- Bagging (Bootstrapping aggregating)
배깅은 Bootstrap Aggregating의 줄임말로, 중복을 허용하는 샘플링을 이용하여 여러 개의 분류기를 학습시키고, 그 결과를 투표(voting)하여 가장 많은 표를 얻은 결과를 최종적인 예측 결과로 선택하는 방식입니다. 각 분류기들은 서로 독립적으로 학습되며, 개별 분류기의 오차는 전체 모델의 오차를 감소시키는 데 기여합니다. 대표적인 예로는 랜덤 포레스트(Random Forest)가 있습니다.
bootstrapping 을 이용해 무언 갈 하는 것을 말한다.
- boosting
100개중 80개를 맞추는 모델이 있다면 나머지 20개의 잘 안되는 data의 모델(weak learner)을 만들고 연결시켜 하나의 큰 strong learner로 만드는 것을 말한다.
2) Gradient Descent Methods
전통적인 Descent Methods
- SGD(stochastic gradient descent)
- 엄밀히 말하면 10만개 data가 있다면 그중 1개를 뽑아 gradient를 update하는 것을 말한다.
- mini-batch gradient descent
- 10만개의 data가 있다면 그 중 batch size 만큼 sample을 뽑아 gradient를 update한다.
- batch gradient descent
- 10만개 data를 한 꺼번에 이용하여 gradient를 update한다.
batch size를 작게하는 것이 좋다는 것이 알려져 있다. batch size 가 작다면 flat minimizers가 되는데, 그러면 test data와 train data 의 loss 차이가 별로 나지 않게 된다.
하지만 batch -size를 크게 하면 sharp minimizers가 되는데 이 때 training function이 극소점에 있으면 testing Function은 loss값이 높은 것을 볼 수 있다.
이제 다른 optimizer에 대해 알아보자.
1. SGD
2. Momentum
3. Nsterov Accelerated Gradient
4. Adagrad
5. Adadelta
6. RMSprop
7. Adam
3) Regularization
언젠가 pytorch 커뮤니티에서 우스갯소리로 지도학습이 아니라 '강제학습'이라고 하는 이야기를 들은 것 같다. 이는 너무 학습 data에 치우치게 학습해 일반적인 test data에 적용이 안되는 현상을 농담처럼 말한 것 같다. 따라서 Regularization은 과도한 학습을 막기 위해 학습을 방해하는 규제를 하는 방법이다.
1. Early stopping
말 그대로 일찍 training을 멈추는 방법이다.
2. Parameter norm penalty
3. Data augmentation
data를 지지고 볶아서 더 만들어내는 것
4. Noise robustness
5. Label smoothing
mix up
cut mix
6. Drop out
7. Batch normalization
'AI > Deep Learning' 카테고리의 다른 글
| Generative Model 2(VAE, GAN, Diffusion) (0) | 2023.03.26 |
|---|---|
| Generative Model (Autoregressive model) (0) | 2023.03.24 |
| Transformer (0) | 2023.03.23 |
| RNN(Recurrent Neural Networks) (0) | 2023.03.22 |
| Neural Network & MLP(Multi Layer Perceptron) (0) | 2023.03.20 |