

기본적으로 3개의 채널의 convolution 연산을 하게 되면 28 * 28의 한개의 채널이 나오게 된다.

만약 여러개의 채널을 만들고 싶다면 여러개의 filter를 만들어서 convolution 연산을 하면 된다.

Convoution에서의 parmeter의 갯수는 filter의 parameter수가 된다.

CNN은 Convolution, pooling layer, Fully connected layer로 이루어져 있다.
Convolution과 pooling layer는 유용한 정보를 추출하는 역할을 하고 Fc는 마지막 decision making을 담당한다.(ex classification)
1 X 1 Convolution 연산
1 * 1이라는 것은 영역을 보는것이 아니라 한 pixel만 보는것이다. 따라서 채널만 줄이는 것이다.
왜 1 * 1 convolution 연산을 사용하는가?
1. Dimension reduction
2. 깊이는 깊게 쌓고 parameter의 갯수는 줄이기 위해서 사용한다.
이제부터 CNN 의 Network를 보겠다. 점점 층은 깊어지고 parameter의 갯수는 낮아질 예정인데 어떻게 그것을 했는지 볼 예정이다.
1) AlexNet

총 8개이 층으로 이루어져있다. 5개는 convolutional layer이고 3개는 dense layers이다.
또 11 x 11 x 3 filter를 사용했다.(요즘엔 사용 X)
Alex넷의 Key ideas
1. ReLU 활성화함수 사용
- non- linear 함수이다.
- gradient vanishing X
2. GPU 2개 사용
3. LRN 사용(요즘엔 사용 X), Overapping pooling
4. Data augmentation
5. drop out
지금 보면 당연한 것들이 많지만 그 당시에는 당연하지 않았기에 일반적으로 잘되는 기준을 잡아줬다고 할 수 있다.
2) VGGNet
1. 3 x 3 convolution filters만 사용(with stride 1) 중요한 것.
2. 1 x 1 convolution for fully connected layers
3. dropout(0.5)
4. 레이어 갯수에 따라 VGG16, VGG19 도 있다.(AlexNet보다 깊음)
왜 3 x 3 convolution filter를 사용했나??

convolution filter의 크기가 커지면 좋은 점은 한번에 고려할 수 있는 영역 범위(receptive filed)가 넓어진 다는 것이다.
만약 3 x 3 convolution 연산을 2번 적용시킨다면 receptive file는 5 x 5 convolution연산을 한것과 동일해진다. receptive filed는 같지만 parameter의 수는 줄어드는 것을 알 수 있다.
즉 VGGNet은 알렉스넷과 달리 3 x 3filter만을 활용하여 parameter의 수를 줄일 수 있었다.
3) GoogLeNet

1. 구글넷은 1 x 1 convolution을 사용하여 parameter 숫자를 줄였다.
2. NIN구조: network 안에 network 가 있는 구조
3. Inception Block 사용
구성:
1. Stem network: vanilla convolution networks 로 이루어져있다.
2. Inception Block을 쌓았다.
3. 중간 중간 분류기를 나주었다.(Vanishing gradient문제를 해결하기 위해 주사기처럼 꽂아줌, 이러한 것들은 학습에서만 사용한다.)
4. 마지막 출력은 한개의 FC layer로 되어있다.
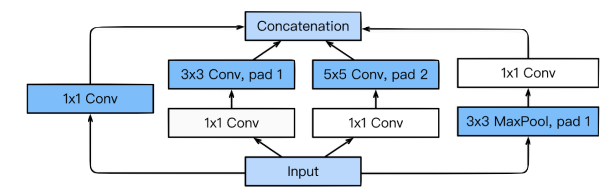
Inception block -> 다양한 크기의 filter를 사용했는데 이를 통해 여러측면에서 activation 을 관찰 할 수 있다. 그 후 filter의 ouput 들은 Concatenation channel방향으로 시켜주었다.
그러나 위의 연산을 한다면 network size가 커지고 계산하는 데 오래걸린다. 따라서 1 x 1 convolution 연산(bottle neck layer)을 해주었다. 따라서Inception block의 parameter의 수를 줄여준다.
어떻게 해서 줄여주냐??
1 x 1 convolution 을 사용하여 채널방향으로 dimension을 줄였기 때문이다.
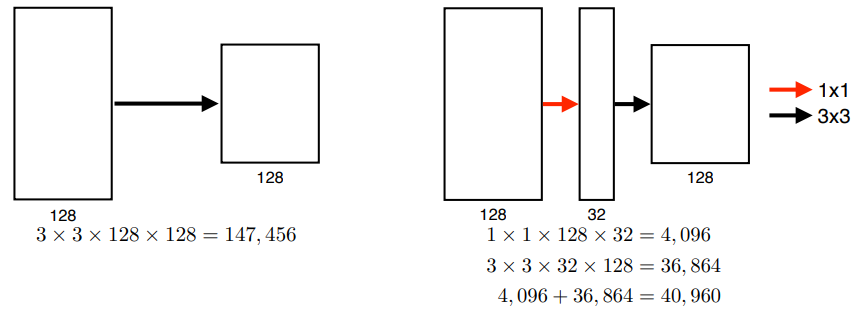
위 그림을 보면 1x 1 convolution 을 껴줬을 뿐인데 parameter수가 줄어든 것을 알 수 있다.
4) ResNet
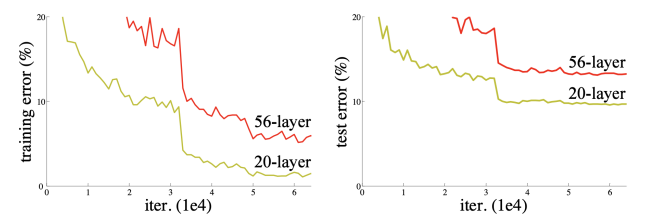
연구자들은 neural network의 층을 깊이 쌓을 수록 parameter수가 많아지기 때문에 Overfitting 이 일어날 것 이라고 생각했다. Overfitting 이란 학습을 하면할 수록 train error는 줄어드는데 test error는 반대로 늘어나는 것을 말한다. 하지만 위 그래프를 보면 Overfitting 은 일어나지 않았다는 것을 알 수 있다. 오히려 Overfitting 보다는 degrade rapidly 즉 학습이 더 잘 안되는 현상이 나타났다.
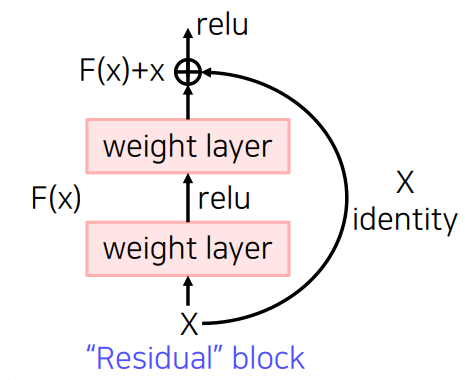
따라서 ResNet은 identity map(skip connection) 이라는 것을 추가했다.
identity map(skip connection)
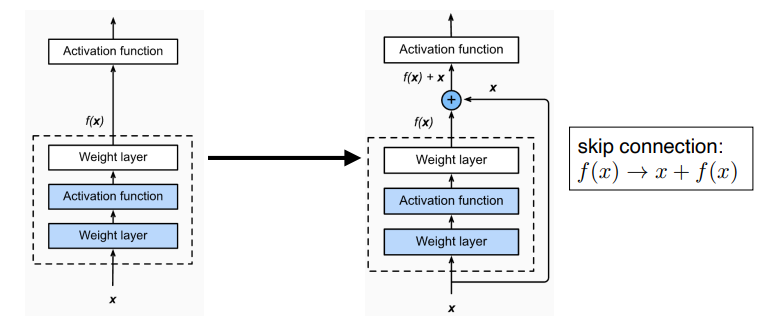
x 라는 input 을 결과값 f(x) 에 더 해준다. 그래서 이를 통해 얻으려는 것은 input과의 차이점만 학습 하는 것이다.
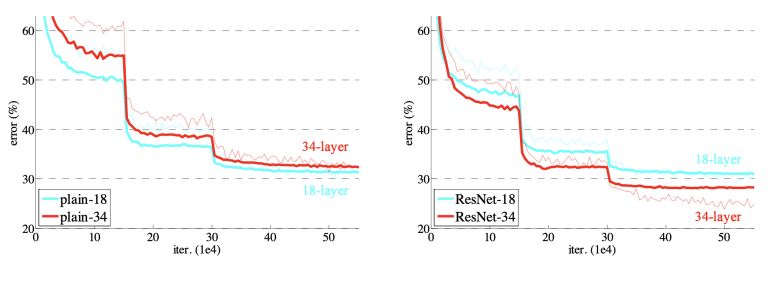
이를 통해 깊은 네트워크도 더 학습을 잘 시킬 수 있게 되었다.

원래 논문에서는 Batch Norm을 3 x 3 convolution 뒤에 적용했지만 이것에 대한 순서는 논쟁이 있다. 또 1 x1 Conv로 차원을 맞춰줘야 해서 이렇게 적용시키는 것은 projected shortcut이라고 하는데 잘 사용하지 않는다.
ShortCut connection
이러한 Residual Block을 통해 오차 역전파가 소실되어도 다른 곳으로 전달 될 수 있게 된 것이다.
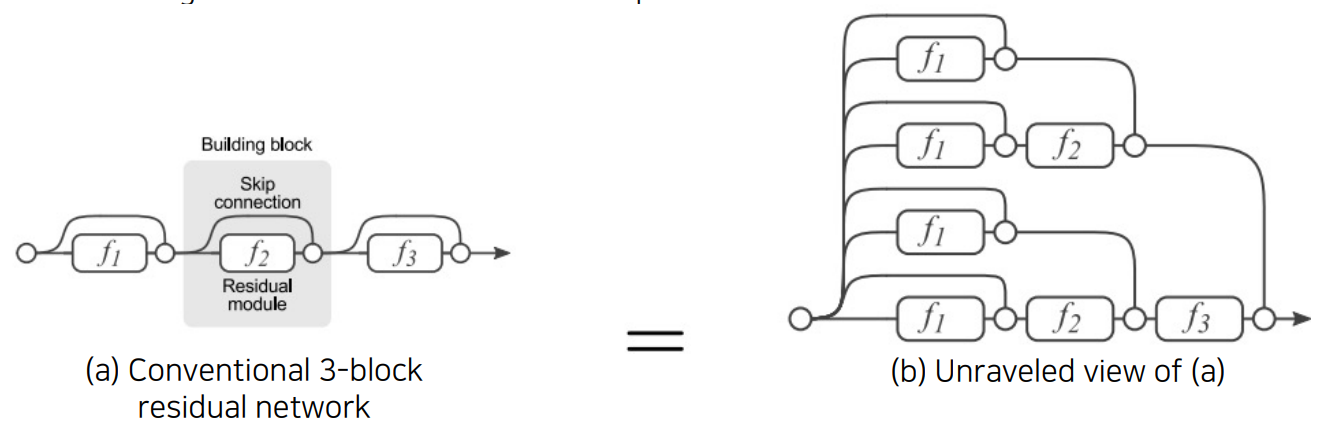
이러한 Residual Block을 한개 설치할 때마다 2배씩 겨우의 수가 생기게된다. 가는 길이 많아질수록 살아남는 역전파의 수도 많아질 수 있게 된다.
bottlenneck architecture
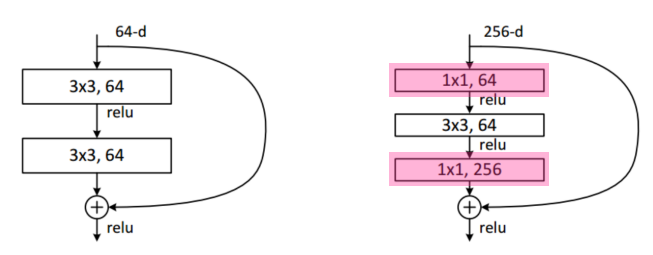
여기서도 1 x 1을 Google net 처럼 활용하였다. 3 x 3 convolution 연산전에 parameter수를 줄이고 다시 연산 후 1 x1 연사을 해주면서 차원을 늘려준다.
여기까지 정리를 해보면 갈수록 parameter 수는줄고 성능은 좋아지는 것을 확인할 수 있다. 먼저 작은 filter size를 이용해 receptive filed 를 늘리며 1 x 1연산을 통해 parameter 채널 수를 맞추는 식으로 parameter를 줄였다.
Resnet 의 구조
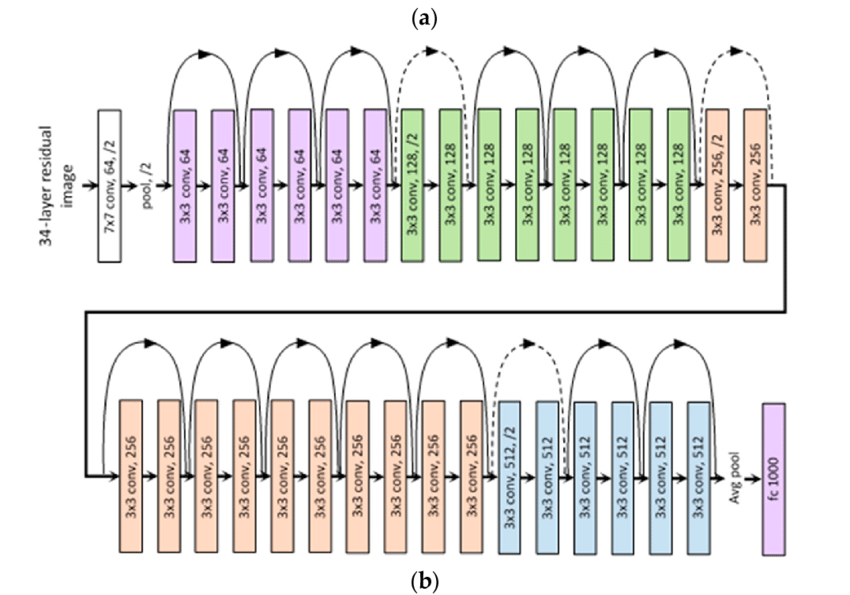
1. He 초깃값 사용(초기값을 설정해주지 않으면 초반에 너무 커지는 문제 발생)
2. Residual block을 쌓은 형태 각 Residual block마다 2개의 3 x 3 conv layer를 가지고 있다. 그리고 각 conv layer이후 batch norm을 적용시켜주었다.
3. 각 색깔로 이루어진 영역을 벗어날 때마다 filter의 갯수는 2배로 올려주고 pooling layer 대신 strided convolution 을 통해 공간해상도를 감소시킨다.
4) DenseNet
densenet은 더하는 것 대신에 채널 축으로 concatenation 을 사용했다.
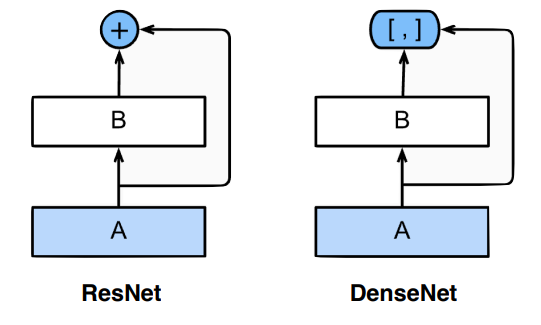
Convolution 연산에서 그동안 다 더해줬다면 여기서는 더하면 섞이니까 따로따로 분리시켜 놓는 것이다. 이를 통해 상위 layer도 하위 layer의 정보를 확인할 수 있게 됐다.

그러나 concat 하게 되면 길이가 2배로 계속 증가한다. 즉 채널이 2배씩 증가한다. 그러면 Convolution feature map의 channel 도 같이 커져서 parameter 수도 증가한다.

따라서 Dense Net은 2가지 Block 이 있는데 다음과 같다.
Dense Block 을 통해 channel 을 기하급수적으로 키운다음에 Transition Block 에서 Batch Norm을 적용후 1 x 1 convolution 연산을 통해 channel을 다시 줄인다. 이것을 계속 반복하게 된다.
요약
VGG: 3 x 3 convolution 연산만 사용
GoogLeNet: 1 x 1 convolution 사용해서 param 수 줄임
ResNet: skip connection을 통해 깊은 층도 train잘되게 함.
DenseNet: concatenation을 통해 성능향상
5) SENet
6) EfficientNet
7) Deformable convolution
Image classification 정리
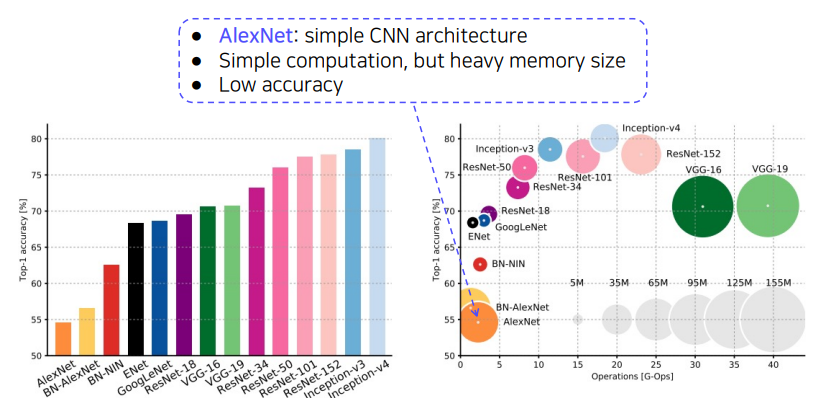
위 그래프에서 보면 Alexnet은 모델이 무겁고 정확도 또한 낮은 것을 알 수 있다.
또 VGGNet같은 경우는 계산이 느리고 모델도 무거운 것을 알 수 있다.
GooggLeNet(Inception-v4)같은 경우는 ResNet 보다 정확도도 높고 계산도 빠르며 모델 또한 가벼운 것을 알 수 있다.
따라서 GoogleNet은 Image Classification에서 가장 효율적인 모델로 꼽히지만 구현하기 복잡하다는 단점이 있다. 그래서 GoogLeNet 대신에 VGGNet 이나 ResNet 또한 많은 tasks에서 back bone 모델로 활용된다.
'AI > Deep Learning' 카테고리의 다른 글
| CNN(Semantic Segmentation, Detection) (0) | 2023.03.26 |
|---|---|
| Generative Model 2(VAE, GAN, Diffusion) (0) | 2023.03.26 |
| Generative Model (Autoregressive model) (0) | 2023.03.24 |
| Optimizer (0) | 2023.03.24 |
| Transformer (0) | 2023.03.23 |