
1) Multi-Modal learning Overview
Multi-Modal-learning이란 다른 특성을 갖는 data(ex. text, sound)를 같이 활용하는 것을 말한다.
이러한 Multi-Modal이 마주하는 challenge는 다음과 같다.
1. Different representations between modalities

- data간의 표현양식이 다르다. 이를 테면 audio 같은 경우는 1d로 표현되고 Image 는 2d 형태로 표현된다. Text 의 경우 embdding vector로 표현되기 때문에 각각에 특성에 맞게 다뤄야한다.
2. Unbalance between heterogeneous feature spaces

- feature space에 대한 특징이 unbalance 하다.
예를들어 위의 텍스트에 매칭되는 이미지는 한가지만 있는것이 아니라 1 : N 의 관계로 굉장히 많다. 반대의 경우도 마찬가지이다.
3. model be biased on a specific modality

또한 모든 modality 에 대해 공평하게 학습되지 않을 수 있다. 예를들어 모델이 시각적인 정보를 더 많이 쓰는 것이 성능이 좋다고 학습해 버리면 다른 까다로운 data는 안쓰게 되고 이렇게 모델이 편향적으로 학습될 수 있다.
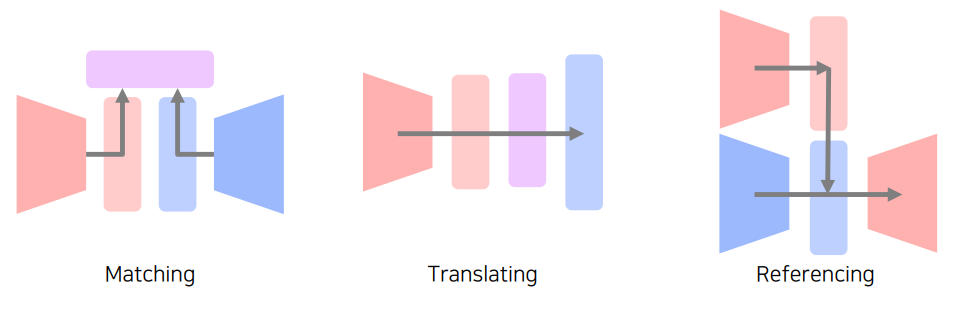
그럼에도 Multi-Modal은 중요하기 때문에 많이 연구되었다. 이러한 다른 data를 다루기위한 일정 패턴이 존재한다.
Matching : 2개의 서로다른 type을 공통된 embedding space로 보내 matching 할 수 있게 한다.
Translating: Modality 를 다른 modality로 translate한다.
Referencing: 다른 Modality 를 참조해서 더좋은 결과를 내게 한다.
2) Visual data & Text
1. 먼저 Text 데이터를 어떻게 다루는지 알아보자.

text data는 Character 단위로 해석하는 것이 아니라 단어 레벨에서 사용한다. 이러한 text를 multi-dimension embedding 된 형태로 표현한다.
이러한 embedding된 vector 가 있다고 할 때 몇가지 특성을 갖게 된다. 예를 들어 위의 2차원으로 관계를 보면 cat 과 kitten 은 유사하기 때문에 가까이 붙어있는 것을 알 수 있고 이와 관련성이 적은 houses는 멀리 떨어져 있는 것을 알 수있다. 또 man 과 woman 사이의 거리를 king 에 적용시키면 king, queen 도 man 과 woman의 관계를 가지게 되는 등의 단어의 특성에 따라 embedding 이 된다는 것을 알 수 있다.
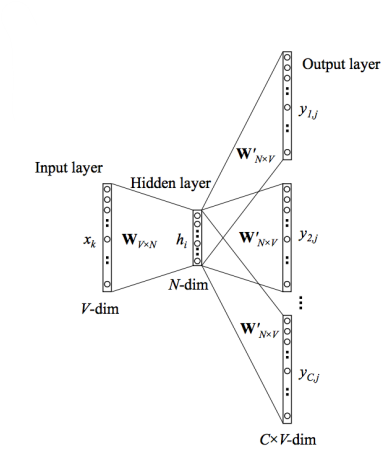
그리고 word2vec 의 skip-gram-model 을 이용해 단어관의 관계에 대해 학습한다.
Word2Vec은 자연어 처리에서 가장 유명한 알고리즘 중 하나입니다. Word2Vec 모델은 단어를 벡터로 변환하여 단어 간 유사성을 계산하고, 이를 통해 문서 분류, 자연어 이해 등의 작업을 수행할 수 있습니다.
Skip-gram 모델은 Word2Vec의 두 가지 모델 중 하나입니다. Skip-gram 모델은 주어진 단어로부터 주변 단어를 예측하는 방식으로 학습됩니다. 예를 들어, "the cat sat on the mat"이라는 문장이 있다면, "cat"이 입력으로 주어졌을 때, Skip-gram 모델은 "the", "sat", "on", "the", "mat"과 같은 주변 단어를 예측하려고 시도합니다.
Skip-gram 모델의 학습 과정에서는 입력 단어에 대한 임베딩 벡터가 생성됩니다. 이 임베딩 벡터는 해당 단어의 문맥 정보를 포함하고 있으며, 이를 통해 단어 간의 유사성을 계산할 수 있습니다. 이렇게 생성된 임베딩 벡터는 다양한 자연어 처리 작업에서 유용하게 사용될 수 있습니다.
2-1. Joint Embedding
Joint embedding은 다른 도메인에서 나온 서로 다른 데이터들을 동시에 임베딩하여 공통의 잠재 공간(Latent Space)으로 투영하는 기술입니다.
예를 들어, 이미지와 자연어처리의 두 가지 도메인이 있을 때, Joint embedding을 사용하면 이미지와 텍스트를 같은 잠재 공간에 투영하여 각 도메인에서 나온 데이터들 간의 관계를 파악할 수 있습니다. 이를 통해 이미지와 텍스트 간의 유사성을 계산하거나 이미지에 대한 캡션 생성 등의 작업을 수행할 수 있습니다.
Joint embedding은 딥러닝 모델을 사용하여 구현됩니다. 일반적으로 이미지 데이터는 Convolutional Neural Network (CNN)을 사용하여, 자연어처리 데이터는 Recurrent Neural Network (RNN)이나 Transformer를 사용하여 임베딩을 생성합니다. 그 다음, 생성된 임베딩은 같은 공간에 투영됩니다.
1. Image tagging

본격적으로 Image tagging task를 먼저 보자. Image tagging 은 tag를 통해 imae를 생성할 수도 있고 image를 통해 tag를 찾을 수도 있다.
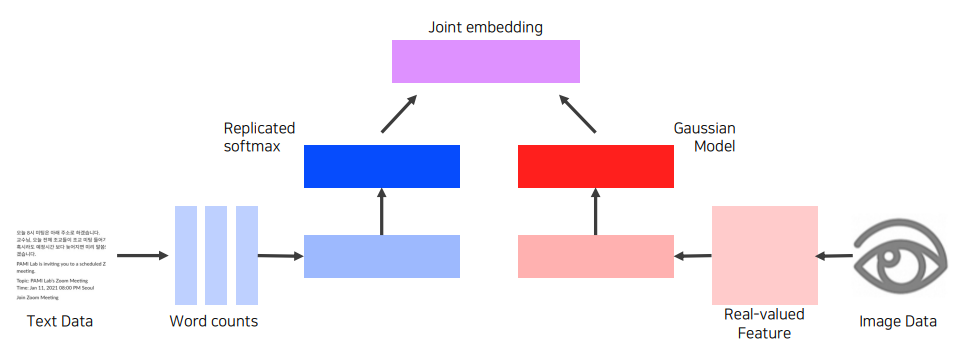
먼저 Text data같은 경우 위에서 본 Word2Vec 이나 다른 net work 를 통해 고정된 크기의 vector로 표현해준다.
Image Data 또한 CNN 을 사용할 수도 있고 어쨋든 Text data와 같은 dimension의 고정된 크기의 vector로 표현해준다.
그리고 이런 같은 크기의 vector를 서로 호환 할 수 있게 Joint embedding 해주는 것이 특징이다. 예를 들어 만들어진 두 벡터가 유사하다면 작은 distance를 만든 다던지 유사하지 않다면 큰 distance를 갖게 해주는 특징을 만드는 것이 Joing embedding이라고 한다.

그래서 위 같은 경우에도 text 와 image는 서로 다른 space 에 있지만 같은 공간으로 embedding 해주고 만약 pair 사이에 연관성이 있으면 distance 를 좁히고 없으면 distance 를 멀게 하는 느낌으로 학습을 한다. 그래서 두 데이터간 호환성이 있게 되고, push, pull 등으로 distance 로 학습하는 것을 metric learning 이라고 한다.
2. Image & food recipe retrieval

재료의 순서와 같은 Recipe 는 왼 쪽의 RNN계열의 NN을 통해 학습하고 fixed vector를 도출한다.
image 는 CNN 계열의 NN을 통해 학습 결과를 도출한다. 여기서도 위에서보았던 Joing-embedding 의 특징처럼 둘다 같은 크기의 vector로 만들어준다.
그리고 cosin-similarity loss(연관이 높으면 높게, 낮으면 낮게)를 통해 학습을 한다. 그다음 sematic regularization loss는 cosin loss로 안되는 점을 보완해준다고 생각하면 된다.
2-2. Cross modal translation

'AI > CV' 카테고리의 다른 글
| Vision + Language Transformers, Unified Transformer (0) | 2023.04.09 |
|---|---|
| Vision Transformer (0) | 2023.04.08 |
| 3D에 대해 이해해보자 (0) | 2023.04.06 |
| Conditional Generative Model (0) | 2023.04.04 |
| Instance Panoptic Segmentation (0) | 2023.03.31 |