
-
1) Conditional generative model
-
이것은 무엇인가??
-
-
Generative model VS Conditional generative model
-
응용사례
-
Generative model 을 복기해보자.
-
-
Conditional GAN 응용 사례
-
-
2) Image Translation GANs
-
1. Pix2Pix
-
-
2. CycleGAN
-
3. Perceptual loss
-
GAN loss vs Perceptual loss
-
1. Feature reconstruction loss
-
2. Style reconstruction loss
1) Conditional generative model
이것은 무엇인가??
조건이 주어졌을 때 image를 해석해주는 것을 말한다.

예를 들어 위와 같이 실제 이미지를 가방으로 번역하는 함수가 있다고 한다. 이러한 모델은 조건에 해당하는 결과가 나오는 모델이다.
generative model 자체가 확률분포를 모델링하는 기법이기 때문에 확률분포로 표현할 수 있다. 그리고 이러한 조건이 주어지면 확률분포가 확률이 높은 구간의 image가 sampling 되어 나올 것이다.
Generative model VS Conditional generative model

Generative model 같은 경우에는 생성만 가능했지 이것을 조작하지는 못했다.
하지만 Conditional genrative model 같은 경우 User의 의도가 반영되어 sampling할 수 있다는 차이점이 있다.
응용사례
1. audio super resolution
- 저퀄리티의 audio를 고퀄리티의 audio로 반환한다.
2. machine translation
3. article genration with the title
Generative model 을 복기해보자.
가짜 이미지를 더 잘 만들기 위해 학습하는 Generator 와 그런 진짜, 가짜를 더 잘 구분하기 위해 학습하는 Discriminator가 서로 경쟁하며 학습하는 Adversarial Network 였다.
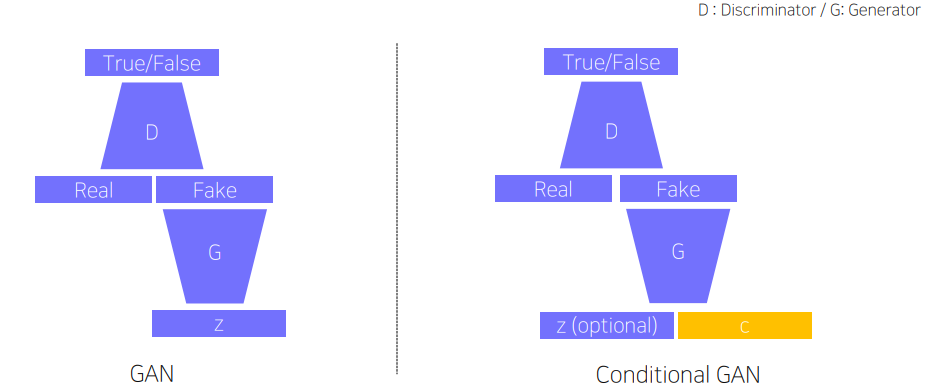
이 때 Conditional GAN 같은 경우도 크게 다르지 않다. 다만 Condition 정보를 제공하기 위한 input이 존재한다는 차이점이 있다.
Conditional GAN 응용 사례
style tranform, super resolution, Colorization 등등이 있다.
1. Super Resolution

Super Resolution 이란 저해상도 이미지를 고해상도로 transform 하는 것을 말한다.
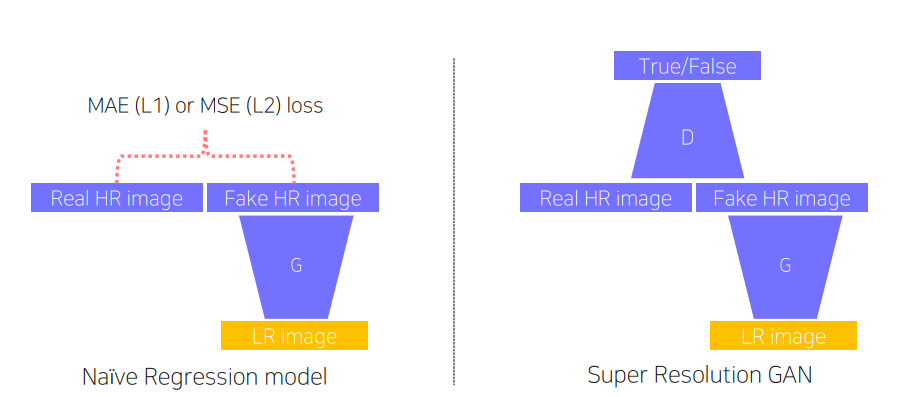
이 때 이러한 Super Resolution에는 반드시 GAN 을 사용해야하는 것은 아니다. 앞의 사례와 같이 loss(MAE, MSE)를 이용한 CNN을 사용한 Regression model을 사용할 수 있다.
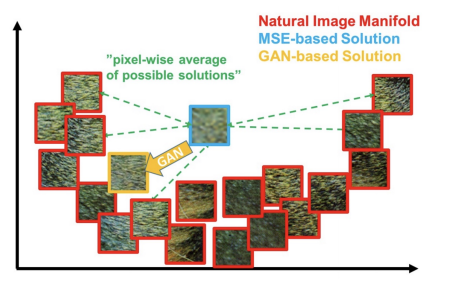
MAE나 MSE loss를 사용한 경우 GAN 보다 blurry 한 이미지등 조금 떨어지는 퀄리티의 output이 나올 수 있다. 왜냐하면 이러한 loss 자체가 pixel 자체의 차이를 이용한 평균을 사용하기 때문에 출력결과가 비슷한 error의 patch가 다수 존재하게 된다. 따라서 구분성이 떨어진다. 즉 model이 편리한 해결책을 사용하여 결과를 내놓는 것이다.


예를 들어 흑백 이미지 2개를 생성해는 이미지가 있다고 하자. 이 때 Regression 모델의 경우 학습을 진행할 경우 회색의 output 을 내놓게 된다. 왜냐하면 중간으로 가야 error가 적당히 낮은 값이 나오기 때문이다. CNN 이 자신이 유리하게 학습을 진행한 것이다.
반면 GAN 같은 경우 회색같은 결과가 나오게 되면 Discriminator 가 이 딴 결과는 본적 없다고 가짜로 잡게 된다. Generator는 따라서 더 사실과 같은 결과를 내놓기 위해 흑이나 백으로 명확하게 판별하게 된다.
2) Image Translation GANs

- 다른 style에 맞는 이미지 변환한다.
- 일반적으로 input 해상도와 output 해상도를 유지한다.
1. Pix2Pix

Pix2Pix에서 GAN loss 뿐만 아니라 L1 loss 를 쓰는 이유
1. GAN loss 만 사용시 입력된 x, y 쌍을 직접 비교하지 않는다. 얘는 독립적으로 discriminate 해서 real 인지 fake인지 판별한다. 따라서 입력에 뭐가 들어와도 y를 보고 판별하지 않기 때문에 y와 비슷한 결과를 나오게 하는 것이 불가능하다. 따라서 L1 loss 를 사용하며 y와 비슷한 결과값이 나오게 하기 위함이다.
2. 이 논문이 나올 당시 GAN 의 학습은 상당히 불안정했다. 따라서 학습의 안정성을 위해 L1 loss를 사용했다.

하지만 Pix2Pix의 경우 Sueprvised Learning이기 때문에 Pair data가 필요했다. 그러나 항상 pair data를 찾는 것은 힘들기 때문에 Unpair data를 활용하는 방법이 필요했다.
2. CycleGAN

CycleGAN은 위와같은 문제를 해결하였다. Pair의 data가 필요한 것이 아니라 각 쌍의 data를 준비한 후 2가지로의 변환을 많이 함으로써 학습시켰다.

CycleGAN은 2가지 loss를 사용했다. GAN loss 와 Cycle-consistency loss이다. GAN loss의 경우 방향성이 존재하고 동시에 같이 학습을 시켰다. Cycle-consistency loss의 경우 뒤에서 더 살펴보자.

GAN loss 는 4가지 term으로 구성되어있고 각각 2개의 generator와 2개의 Discriminator로 이루어져 있다.

만약 이러한 GAN loss만 사용하게 된다면 Mode Collapse 라는 문제점이 발생한다. 즉 Input 상관없이 1개의 Output만 출력하게 되는 것이다.
예를 들어 G_X가 계속해서 똑같은 가방을 생성한다면 D_Y는 가방을 잘 생성한다고 판단할 수 있다. 그리고 G_Y는 다시 이미지를 바꿀 때 가방이미지를 주기 때문에 D_X도 잘 판단한다고 생각해 한가지만 계속해서 만들어 낼 수 있다.
이런 문제를 해결하기 위해 Cycle consistency loss가 필요하다.

이러한 Cycle-consistency loss는 X 가 다시 X로 돌아올 때 원본이 복원되어야한다는 것을 loss로 설정한다. 그리고 이는 X, Y 둘다 적용된다. 이러한 loss는 sueprvision 이아닌 self-supervision이라고 할 수 있다.
3. Perceptual loss
GAN은 train 하기 어렵다. 그럼에도 쉬운 regression 을 쓰지 않고 GAN을 쓰는 이유는 quality 가 좋기 때문이다. 그렇다면 GAN을 사용하지 않고 quality 가 좋은 output을 내는 다른 방법도 존재한다.

GAN loss vs Perceptual loss
GAN loss(Adversary loss)
- train 하기 어렵고 code로 구현하기 어렵다.
- pre-train network가 필요없다.
- 미리 train 된 네트워크가 필요없으므로 다양한 data에 적용할 수 있다.
Perceptual loss
- 학습하기 쉽고 code로 구현하기 쉽다.( 역전파, 순전파 만 사용)
- pre-train network가 필요하다.

Image Transform Net: 1가지의 style로만 변환이 가능하다.
network 특징
1. 먼저 미리 train 된 VGGNet을 이용해 feature를 뽑는다.
2. 그 후 Style target 과 content target을 이용해 loss를 계산한다.
이 때 VGGNet의 weight는 freeze 시키고, y_hat에 대한 weight 만 update한다.
2가지 loss 에 대해 살펴보자.
1. Feature reconstruction loss

transform 된 이미지가 content(input X)를 유지하고 있는지 확인하는 loss이다.
2. Style reconstruction loss

- style을 transform 하는 loss이다.
위의 loss 와 다르게 feature를 바로 loss계산하지 않고 style을 살리기 위해 따로 과정을 거친다.
Gram matrices의 경우 channel x channel로 이루어져있다. 이는 먼저 Feature map을 channel x (width * height) 로 reshape해주고 둘을 내적해주어 구한다. 이것의 의미는 먼저 reshape을 통해 각 채널간의 관계가 얼마나 자주 나타나는지를 나타내 주는 것이다. 앞에서 channel 은 detector(ex 눈 코입 검출)의 역할을 한다고 했다. 따라서 이러한 channel 의 관계로 나타내 내적을 해주어 두 style 간의 유사도를 보고 style을 따라가는 식으로 loss를 정할 수 있다. 이러한 loss는 network 중간중간 계산된다.
'AI > CV' 카테고리의 다른 글
| Vision Transformer (0) | 2023.04.08 |
|---|---|
| 3D에 대해 이해해보자 (0) | 2023.04.06 |
| Instance Panoptic Segmentation (0) | 2023.03.31 |
| CNN Visualization (0) | 2023.03.30 |
| Object Detection (R-CNN, YOLO, SSD, DETR, Transformer) (1) | 2023.03.29 |
1) Conditional generative model
이것은 무엇인가??
조건이 주어졌을 때 image를 해석해주는 것을 말한다.
예를 들어 위와 같이 실제 이미지를 가방으로 번역하는 함수가 있다고 한다. 이러한 모델은 조건에 해당하는 결과가 나오는 모델이다.
generative model 자체가 확률분포를 모델링하는 기법이기 때문에 확률분포로 표현할 수 있다. 그리고 이러한 조건이 주어지면 확률분포가 확률이 높은 구간의 image가 sampling 되어 나올 것이다.
Generative model VS Conditional generative model
Generative model 같은 경우에는 생성만 가능했지 이것을 조작하지는 못했다.
하지만 Conditional genrative model 같은 경우 User의 의도가 반영되어 sampling할 수 있다는 차이점이 있다.
응용사례
1. audio super resolution
- 저퀄리티의 audio를 고퀄리티의 audio로 반환한다.
2. machine translation
3. article genration with the title
Generative model 을 복기해보자.
가짜 이미지를 더 잘 만들기 위해 학습하는 Generator 와 그런 진짜, 가짜를 더 잘 구분하기 위해 학습하는 Discriminator가 서로 경쟁하며 학습하는 Adversarial Network 였다.
이 때 Conditional GAN 같은 경우도 크게 다르지 않다. 다만 Condition 정보를 제공하기 위한 input이 존재한다는 차이점이 있다.
Conditional GAN 응용 사례
style tranform, super resolution, Colorization 등등이 있다.
1. Super Resolution
Super Resolution 이란 저해상도 이미지를 고해상도로 transform 하는 것을 말한다.
이 때 이러한 Super Resolution에는 반드시 GAN 을 사용해야하는 것은 아니다. 앞의 사례와 같이 loss(MAE, MSE)를 이용한 CNN을 사용한 Regression model을 사용할 수 있다.
MAE나 MSE loss를 사용한 경우 GAN 보다 blurry 한 이미지등 조금 떨어지는 퀄리티의 output이 나올 수 있다. 왜냐하면 이러한 loss 자체가 pixel 자체의 차이를 이용한 평균을 사용하기 때문에 출력결과가 비슷한 error의 patch가 다수 존재하게 된다. 따라서 구분성이 떨어진다. 즉 model이 편리한 해결책을 사용하여 결과를 내놓는 것이다.
예를 들어 흑백 이미지 2개를 생성해는 이미지가 있다고 하자. 이 때 Regression 모델의 경우 학습을 진행할 경우 회색의 output 을 내놓게 된다. 왜냐하면 중간으로 가야 error가 적당히 낮은 값이 나오기 때문이다. CNN 이 자신이 유리하게 학습을 진행한 것이다.
반면 GAN 같은 경우 회색같은 결과가 나오게 되면 Discriminator 가 이 딴 결과는 본적 없다고 가짜로 잡게 된다. Generator는 따라서 더 사실과 같은 결과를 내놓기 위해 흑이나 백으로 명확하게 판별하게 된다.
2) Image Translation GANs
- 다른 style에 맞는 이미지 변환한다.
- 일반적으로 input 해상도와 output 해상도를 유지한다.
1. Pix2Pix
Pix2Pix에서 GAN loss 뿐만 아니라 L1 loss 를 쓰는 이유
1. GAN loss 만 사용시 입력된 x, y 쌍을 직접 비교하지 않는다. 얘는 독립적으로 discriminate 해서 real 인지 fake인지 판별한다. 따라서 입력에 뭐가 들어와도 y를 보고 판별하지 않기 때문에 y와 비슷한 결과를 나오게 하는 것이 불가능하다. 따라서 L1 loss 를 사용하며 y와 비슷한 결과값이 나오게 하기 위함이다.
2. 이 논문이 나올 당시 GAN 의 학습은 상당히 불안정했다. 따라서 학습의 안정성을 위해 L1 loss를 사용했다.
하지만 Pix2Pix의 경우 Sueprvised Learning이기 때문에 Pair data가 필요했다. 그러나 항상 pair data를 찾는 것은 힘들기 때문에 Unpair data를 활용하는 방법이 필요했다.
2. CycleGAN
CycleGAN은 위와같은 문제를 해결하였다. Pair의 data가 필요한 것이 아니라 각 쌍의 data를 준비한 후 2가지로의 변환을 많이 함으로써 학습시켰다.
CycleGAN은 2가지 loss를 사용했다. GAN loss 와 Cycle-consistency loss이다. GAN loss의 경우 방향성이 존재하고 동시에 같이 학습을 시켰다. Cycle-consistency loss의 경우 뒤에서 더 살펴보자.
GAN loss 는 4가지 term으로 구성되어있고 각각 2개의 generator와 2개의 Discriminator로 이루어져 있다.
만약 이러한 GAN loss만 사용하게 된다면 Mode Collapse 라는 문제점이 발생한다. 즉 Input 상관없이 1개의 Output만 출력하게 되는 것이다.
예를 들어 G_X가 계속해서 똑같은 가방을 생성한다면 D_Y는 가방을 잘 생성한다고 판단할 수 있다. 그리고 G_Y는 다시 이미지를 바꿀 때 가방이미지를 주기 때문에 D_X도 잘 판단한다고 생각해 한가지만 계속해서 만들어 낼 수 있다.
이런 문제를 해결하기 위해 Cycle consistency loss가 필요하다.
이러한 Cycle-consistency loss는 X 가 다시 X로 돌아올 때 원본이 복원되어야한다는 것을 loss로 설정한다. 그리고 이는 X, Y 둘다 적용된다. 이러한 loss는 sueprvision 이아닌 self-supervision이라고 할 수 있다.
3. Perceptual loss
GAN은 train 하기 어렵다. 그럼에도 쉬운 regression 을 쓰지 않고 GAN을 쓰는 이유는 quality 가 좋기 때문이다. 그렇다면 GAN을 사용하지 않고 quality 가 좋은 output을 내는 다른 방법도 존재한다.
GAN loss vs Perceptual loss
GAN loss(Adversary loss)
- train 하기 어렵고 code로 구현하기 어렵다.
- pre-train network가 필요없다.
- 미리 train 된 네트워크가 필요없으므로 다양한 data에 적용할 수 있다.
Perceptual loss
- 학습하기 쉽고 code로 구현하기 쉽다.( 역전파, 순전파 만 사용)
- pre-train network가 필요하다.
Image Transform Net: 1가지의 style로만 변환이 가능하다.
network 특징
1. 먼저 미리 train 된 VGGNet을 이용해 feature를 뽑는다.
2. 그 후 Style target 과 content target을 이용해 loss를 계산한다.
이 때 VGGNet의 weight는 freeze 시키고, y_hat에 대한 weight 만 update한다.
2가지 loss 에 대해 살펴보자.
1. Feature reconstruction loss
transform 된 이미지가 content(input X)를 유지하고 있는지 확인하는 loss이다.
2. Style reconstruction loss
- style을 transform 하는 loss이다.
위의 loss 와 다르게 feature를 바로 loss계산하지 않고 style을 살리기 위해 따로 과정을 거친다.
Gram matrices의 경우 channel x channel로 이루어져있다. 이는 먼저 Feature map을 channel x (width * height) 로 reshape해주고 둘을 내적해주어 구한다. 이것의 의미는 먼저 reshape을 통해 각 채널간의 관계가 얼마나 자주 나타나는지를 나타내 주는 것이다. 앞에서 channel 은 detector(ex 눈 코입 검출)의 역할을 한다고 했다. 따라서 이러한 channel 의 관계로 나타내 내적을 해주어 두 style 간의 유사도를 보고 style을 따라가는 식으로 loss를 정할 수 있다. 이러한 loss는 network 중간중간 계산된다.
'AI > CV' 카테고리의 다른 글
| Vision Transformer (0) | 2023.04.08 |
|---|---|
| 3D에 대해 이해해보자 (0) | 2023.04.06 |
| Instance Panoptic Segmentation (0) | 2023.03.31 |
| CNN Visualization (0) | 2023.03.30 |
| Object Detection (R-CNN, YOLO, SSD, DETR, Transformer) (1) | 2023.03.29 |