
앞의 Object Detection에서 얘기 했듯 Segmentation 은 같은 클래스내의 다른 객체들은 구분하지 못한다. 따라서 이러한 Semantic segmentation + 물체를 구분하는(object detection)을 활용 한 방법이 Instance Segmentation이다.
1) Instance segmentation
1. Mask R-CNN

그전의 Faster R-CNN은 RPN으로 나온 Bounding Box Proposals 를 이용해 RoI pooling 시켜주었다. 이 때 RoI pooling은 정수좌표들만 지원했었는데 Mask R-CNN의 RoIAlign은 정교한 소숫점 pixel level의 pooling 을 지원해 준다.

또 Mask R-CNN은 기존의 Faster R-CNN 에 Mask branch를 합친 형태이다. 그림에서 볼 수 있듯 Bounding box 마다 80개의 class에 대해 Binary mask를 prediction 하는 구조이다. 이 때 80개의 mask중 어떤 mask를 선택할 지는 classification 을 통해 나온 결과를 참조하여 결정한다.
그리고 이는 RoIAlign을 사용해 two-stage-detector에 해당한다고 볼 수 있다.
2. YOLACT(You Only Look At CoefficienTs)

YOLO는 앞에서 봤듯 one -stage detector이다. 따라서 성능은 다소 떨어질 수 있지만 계산속도는 빠르다는 특징을 가지고 있다. 일단 위의 Mask R-CNN은 80개의 클래스에 대한 마스크를 object마다 생성해주었었다.
하지만 YOLACT는 Object 갯수보다는 적게 mask를 생성한다. mask Prototype 들은 mask는 아니지만 mask를 합성해낼 수 있는 soft segmentation의 component라고 말할 수 있다. 즉 재료를 제공하는 것이다. 선형대수적으로 말하면 Span 가능한 basis들이라고 말할 수 있다.
그 후 prediction head에서는 각 mask 재료들을 잘 합성하기 위한 계수를 출력해준다. 그 후 이 계수들과 재료들을 선형결합 해준다.
그래서 각 detection에 적합한 mask map을 출력해준다.
따라서 요러한 YOLACT의 key point는 object 마다 mask를 생성하는 것이 아니라 mask 재료들을 선형결합으로 해서 다양한 mask를 생성해내는 것이다.
3. YolactEdge

YolactEdge는 소형화 된 모바일 시스템 가튼 곳에서도 빠른속도로 동작할 수 있게 제시된 방법이다. 대표적인 특징으로 key frame의 feature를 전달해서 featuremap의 계산량을 줄였다는데에 있다.
2) Panoptic segmentation
Panoptic segmentation 은 Instance Segmentation에서 기능을 추가하면서 발전하였다. 기존의 Instance Segmentation은 움직이는 작은 물체에 초점을 맞춰서 분류를 진행했다. 즉 배경은 잘 캐치하지 못한 다는 점이 있었다. 오히려 배경을 캐치하고 싶을 땐 Semantic segmentation이 더 유리했다. 따라서 Panoptic segmentation은 두 개를 다 캐치해보자는 것에 초점을 두었다.
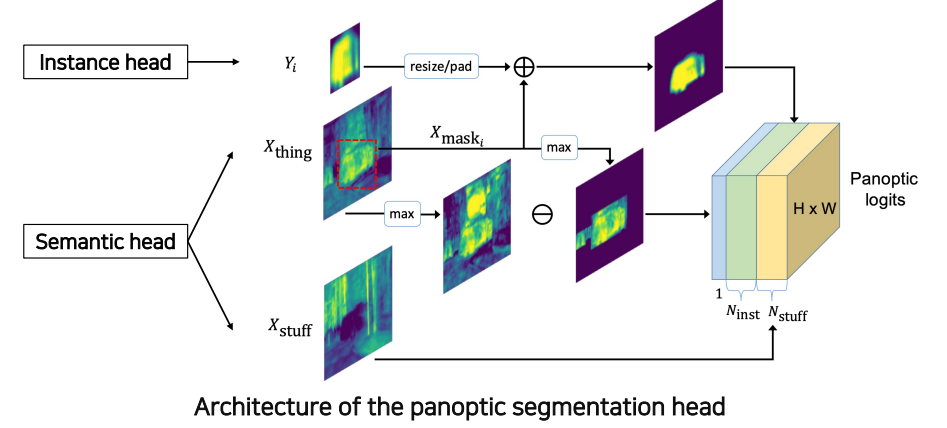
1. UPSNet

먼저 backbone network 는 FPN 구조로 되어있다. 그리고 2개의 head 로 나뉘는데 Semantic Head와 Instance Head이다.
Sematic head에서는 feature map을 추출하기 때문에 FCN구조를 사용한다.
Instance Head는 위의 방법과 마찬가지로 물체를 detection 한 후 Bounding box regression 이 들어가고 mask 를 추출한다.
그리고 이 두가지를 융합해주는 Panoptic Head에서 결과물로 Panptic logits이 나오게 된다.
2. VPSNet
VPSNet은 Panoptic segmentation의 구조를 video로 확장했다.

3) Landmark Localization

landmark localizaiton은 특정물체의 중요하다고 여기는 부분(Landmark)을 정의하고 추적하는 것을 말한다.
1. coordinate regression vs heatmap classification

먼저 landmark를 할 때 coordeinate regression 을 이용해서 하는 방법은 land mark가 N개라면 각 land mark 마다 x, y의 위치를 예측하는 방식으로 진행되었었다. 하지만 이방식의 경우 부정확하고 일반적이지 않다는 문제가 발견되었다. 따라서 대안으로 Heat map classification을 사용하게 된다.
Heat map classification은 각 channel이 각각의 keypoint를 담당하고, 각 key point 마다 class로 생각해 key point의 발생 확률맵을 pixel 별로 classification 하는 방법이다. 이 방법은 성능은 좋지만 계산량이 많다는 단점이 있다.
이러한 heatmap을 표시하기 위한 방법을 알아보자.


landmark 하나가 x, y에 있을 때 heatmap으로 변환 것이다. 가우시안 분포를 씌워서 계산하면 된다.
2. Hourglass network

Hourglass network는 landmark 방법에 맞는 network를 제시해서 만들어진 network이다.
U-Net과 같은 구조를 여러개 쌓은 구조이다. 왜 이렇게 U-net같은 걸 쌓았을 까
먼저 영상을 작게 만들어 receptive filed를 키워야 하기 때문이다. 이것을 통해 landmark를 찾는다. 또 Skip connection으로 low level feature를 참고 할 수 있게하고, 이를 여러번 반복하며 구체화시켜야 하기 때문이다.

그러나 U-NEt과 다른 점도 있다. 일단 U-net과 달리 concat을 하지 않고 더해준다는 점이다. 따라서 dimension이 U-Net처럼 늘지는 않는다. 그래서 가까운 계층을 끌어올 때 Conc layer를 또 통과시켜주어야 한다. 따라서 U-Net보다는 FPN에 더 가까운 구조라고도 볼 수 있다.
3. DensePose

지금까지는 몇몇의 중요한 landmark를 찾는 sparse한 land mark 방법이었는데 좀 더 dense한 landmark를 찾는 방법이다.
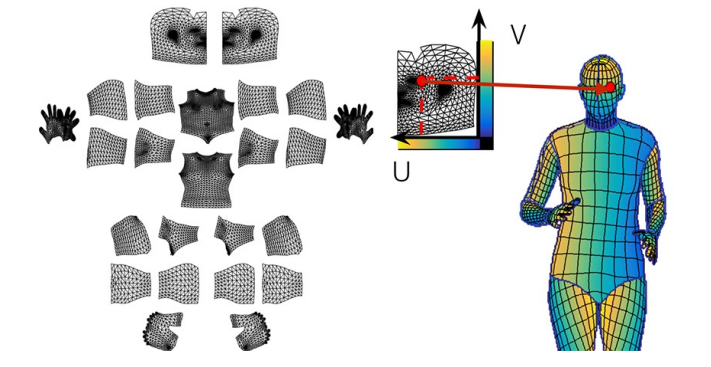
이 때 표기는 UV 맵으로 하는데 UV맵은 2D형태로 펼쳐 이미지형태로 만들어 놓은 좌표 표기법이다.

이러한 DensePose는 Faster R CNN 에 더해 3D surface regression branch를 더해 확장한 모델이다.
4. Retina Face

retinaFace 는 FPN 구조에 Multi-task branches 를 넣어 확장한 모델이다.
위와 같은 구조로 알 수 있듯이 중요한 것은 backbone network에 관심있는 target task에 해당하는 head만 만들어주면 다양한 응용에 적용할 수 있다는 것이다.
4) Detecting objects as key points
앞의 내용에서 Bounding Box를 사용하지 않고 detecting 하는 방법 들이 있다고 했다. 이제 부터 알아볼 것들이 그것들인데 key point를 이용해 detecting을 하는 방법이다.
1. CornerNet


cornerNet은 single stage 에 가까운 구조이다. 정확도가 낮아도 속도를 중시한다. 먼저 Bounding Box를 2개의 point로 정의한다. 그리고 Heatmap에서 먼저 corner를 detection한다. 그 후 Embedding이라는것을 사용하는데 Embedding이란 각포인트가 가진 정보를 표현하는 head이다. 이러한 head를 가지고 같은 embedding point는 같은 object를 가진다고 학습시킨다.
2. CenterNet


위의 Corner Net의 좌표에 Center 좌표를 추가해준다.


위에서 center 좌표를 추가 햇는데 사실 굳이 없어도 2개로도 만들 수 있다. 따라서 center에 width 와 height로 변경해주었따.
'AI > CV' 카테고리의 다른 글
| 3D에 대해 이해해보자 (0) | 2023.04.06 |
|---|---|
| Conditional Generative Model (0) | 2023.04.04 |
| CNN Visualization (0) | 2023.03.30 |
| Object Detection (R-CNN, YOLO, SSD, DETR, Transformer) (1) | 2023.03.29 |
| Sementic Segmentation(FCN, U-Net, DeepLab) (1) | 2023.03.27 |