
1) Transformer
Transformer
1) Transformer Sequential model이 다루기 힘든 문제들 중간에 시퀀스 데이터가 누락되거나, 순서가 바뀌거나 잘리는 문제들은 Sequential model로 다루기가 쉽지 않다. Transformer 는 Sequential model처럼 재귀적
ltsgod.tistory.com
2) Vision Transformer
이러한 transformer 들을 각각 classification, Detection, Segmentation 에 적용한 사례들을 봐보자.
1. ViTs(Vision Transformers) - classification

먼저 각각 patch 들을 나눠준다. 이 때도 각 patch 의 위치가 어디에있었는지 정보를 주기위해 positional encoding을 추가해준다. 이 때 지정해준 함수로 PE를 생성하는 것이 아닌 NN으로 학습시키는 Learnable Positional Encoding 을 사용한다.
기존의 transformer 와 거의 차이가 없지만 맨 앞에 classification token이 한개 들어가게 된다. classfication은 이 토큰을 MLP 에 넣어주어 분류를 진행한다. 이것은 BERT의 class token과 유사하다.
2. DETR(DEtection TRansformer) - Object Detection
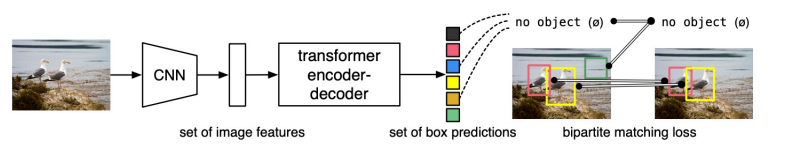
DETR은 object detection 문제를 direct set prediction 형태로 사용한다.
그리고 직접 hand-designed 했던 요소들을 제거 해주는데 예를들어 non-maximum suppression이 있다. non-maximum suppression은 여러개의 Bounding Box 가 나왔을 때 중복을 제거 해주는 방법이다.
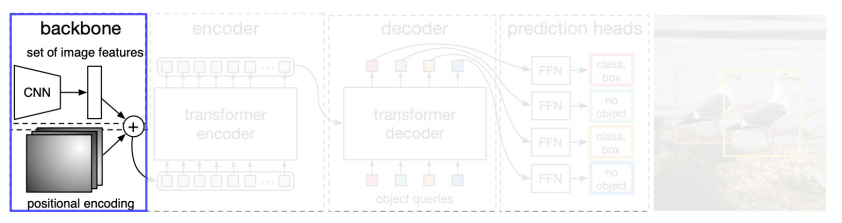
먼저 backbone CNN을 이용해 feature map을 뽑는다. 이 때 positional encoding을 concat해주어 transformer encoder에게 전달해준다. 이러한 CNN을 사용하는 것은 CNN이 feature를 뽑는데에 특화된 NN 이기 때문이다.

Transformer encoder 에서는 1 x 1 conv 연산을 통해 차원을 줄여주고 positional encoding 을 한 번더 concat 해주어 encoder에 투입시켜 준다.
CNN의 결과를 그대로 decoder에 넣지 않는 이유는 다음과 같다.
먼저 CNN의 local receptive filed의 제한이 있기 때문에 각 feature들은 전체적인 맥락은 이해하지못하고 있을 확률이 높다. 따라서 encoder에서 long term dependency를 다 고려해서 enhanced 된 vector로 만들어준 후 decoder에 넣는다.
또 encoder에서 나오는 ouput은 갯수의 변화가 없기 때문에 decoder가 수행하기 좋게 폼을 만들어준다.

Decoder의 경우 encoder의 output 뿐만아니라 object query가 들어가게 되다. 이러한 query 는 어떠한 위치에 어떤 물체가 있는지 물어보는 역할을 한다고 이해하면 된다.(정확히 그건 아니지만) 요러한 object query 또한 학습된 query 들이라고 할 수 있다.

그리고 위에서나온 object query들로 각 영역에 물체가 있는지 없는지 판단하게 된다. 이 때 object query 에 따라 Bounding Box 가 나오기 때문에 원래 이미지에 있는 물체들보다 N을 더 크게 잡아줘야한다. 왜냐하면 training 할 때 setting에 따라 object query의 숫자가 달라지기 때문이다.

이제 이러한 학습된 결과가 실제 정답레이블과 대응되는지 loss를 통해 비교를 해야한다. 이러한 것을 Bipartite matching 이라고 한다.
따라서 위에서 보면 이러한 loss가 bbox loss와 target class loss 로 이루어져 있다.
3. MaskFormer - Segmentation
Mask classification -> 먼저 binary masks를 출력하고 그 mask 에 대해서 하나의 class를 추론하는 방법이다.
Mask classificaition 형태로 formulation 하고 sementic segmentation 으로 transformer를 적용하였다.

먼저 backbone network로 feature map을 추출한다. 이 때 backbone 에서 나온 feature map은 row-resolution image feature map 이다. 이렇게 낮은 해상도의 feature map을 pixel decoder에서 upsampling 해준다. 왜냐하면 segmentation 은 고해상도 이미지가 필요하기 때문이다.

그리고 Decoder에서는 image Feature와 N개의 learnable positional encoding 이 들어오게 된다. 이 부분은 DETR과 비슷하다.
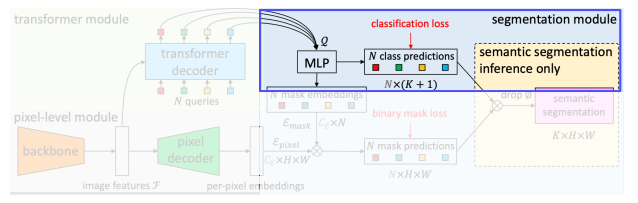
이렇게 나온 query들을 먼저 classification loss를 통해 classification 시킨다. 이 때 no object category도 한개 추가해서 학습한다.



그리고 MLP 에서 mask embedding 도 추출해준다. 이 mask embedding 과 pixel decoder에서 나온 feature map을 내적해준다. 이렇게 해서 binary mask를 출력해준다. 이 때 나온 mask는 class에 대한 정보는 없다. 이러한 mask를 위에서 나온 class prediction 과 결합하여 각각에 대해 K X H X W의 결과가 나오게 된다.
'AI > CV' 카테고리의 다른 글
| Multi-Modal (0) | 2023.04.09 |
|---|---|
| Vision + Language Transformers, Unified Transformer (0) | 2023.04.09 |
| 3D에 대해 이해해보자 (0) | 2023.04.06 |
| Conditional Generative Model (0) | 2023.04.04 |
| Instance Panoptic Segmentation (0) | 2023.03.31 |
1) Transformer
Transformer
1) Transformer Sequential model이 다루기 힘든 문제들 중간에 시퀀스 데이터가 누락되거나, 순서가 바뀌거나 잘리는 문제들은 Sequential model로 다루기가 쉽지 않다. Transformer 는 Sequential model처럼 재귀적
ltsgod.tistory.com
2) Vision Transformer
이러한 transformer 들을 각각 classification, Detection, Segmentation 에 적용한 사례들을 봐보자.
1. ViTs(Vision Transformers) - classification
먼저 각각 patch 들을 나눠준다. 이 때도 각 patch 의 위치가 어디에있었는지 정보를 주기위해 positional encoding을 추가해준다. 이 때 지정해준 함수로 PE를 생성하는 것이 아닌 NN으로 학습시키는 Learnable Positional Encoding 을 사용한다.
기존의 transformer 와 거의 차이가 없지만 맨 앞에 classification token이 한개 들어가게 된다. classfication은 이 토큰을 MLP 에 넣어주어 분류를 진행한다. 이것은 BERT의 class token과 유사하다.
2. DETR(DEtection TRansformer) - Object Detection
DETR은 object detection 문제를 direct set prediction 형태로 사용한다.
그리고 직접 hand-designed 했던 요소들을 제거 해주는데 예를들어 non-maximum suppression이 있다. non-maximum suppression은 여러개의 Bounding Box 가 나왔을 때 중복을 제거 해주는 방법이다.
먼저 backbone CNN을 이용해 feature map을 뽑는다. 이 때 positional encoding을 concat해주어 transformer encoder에게 전달해준다. 이러한 CNN을 사용하는 것은 CNN이 feature를 뽑는데에 특화된 NN 이기 때문이다.
Transformer encoder 에서는 1 x 1 conv 연산을 통해 차원을 줄여주고 positional encoding 을 한 번더 concat 해주어 encoder에 투입시켜 준다.
CNN의 결과를 그대로 decoder에 넣지 않는 이유는 다음과 같다.
먼저 CNN의 local receptive filed의 제한이 있기 때문에 각 feature들은 전체적인 맥락은 이해하지못하고 있을 확률이 높다. 따라서 encoder에서 long term dependency를 다 고려해서 enhanced 된 vector로 만들어준 후 decoder에 넣는다.
또 encoder에서 나오는 ouput은 갯수의 변화가 없기 때문에 decoder가 수행하기 좋게 폼을 만들어준다.
Decoder의 경우 encoder의 output 뿐만아니라 object query가 들어가게 되다. 이러한 query 는 어떠한 위치에 어떤 물체가 있는지 물어보는 역할을 한다고 이해하면 된다.(정확히 그건 아니지만) 요러한 object query 또한 학습된 query 들이라고 할 수 있다.
그리고 위에서나온 object query들로 각 영역에 물체가 있는지 없는지 판단하게 된다. 이 때 object query 에 따라 Bounding Box 가 나오기 때문에 원래 이미지에 있는 물체들보다 N을 더 크게 잡아줘야한다. 왜냐하면 training 할 때 setting에 따라 object query의 숫자가 달라지기 때문이다.
이제 이러한 학습된 결과가 실제 정답레이블과 대응되는지 loss를 통해 비교를 해야한다. 이러한 것을 Bipartite matching 이라고 한다.
따라서 위에서 보면 이러한 loss가 bbox loss와 target class loss 로 이루어져 있다.
3. MaskFormer - Segmentation
Mask classification -> 먼저 binary masks를 출력하고 그 mask 에 대해서 하나의 class를 추론하는 방법이다.
Mask classificaition 형태로 formulation 하고 sementic segmentation 으로 transformer를 적용하였다.
먼저 backbone network로 feature map을 추출한다. 이 때 backbone 에서 나온 feature map은 row-resolution image feature map 이다. 이렇게 낮은 해상도의 feature map을 pixel decoder에서 upsampling 해준다. 왜냐하면 segmentation 은 고해상도 이미지가 필요하기 때문이다.
그리고 Decoder에서는 image Feature와 N개의 learnable positional encoding 이 들어오게 된다. 이 부분은 DETR과 비슷하다.
이렇게 나온 query들을 먼저 classification loss를 통해 classification 시킨다. 이 때 no object category도 한개 추가해서 학습한다.
그리고 MLP 에서 mask embedding 도 추출해준다. 이 mask embedding 과 pixel decoder에서 나온 feature map을 내적해준다. 이렇게 해서 binary mask를 출력해준다. 이 때 나온 mask는 class에 대한 정보는 없다. 이러한 mask를 위에서 나온 class prediction 과 결합하여 각각에 대해 K X H X W의 결과가 나오게 된다.
'AI > CV' 카테고리의 다른 글
| Multi-Modal (0) | 2023.04.09 |
|---|---|
| Vision + Language Transformers, Unified Transformer (0) | 2023.04.09 |
| 3D에 대해 이해해보자 (0) | 2023.04.06 |
| Conditional Generative Model (0) | 2023.04.04 |
| Instance Panoptic Segmentation (0) | 2023.03.31 |