Vision + Language Transformers, Unified Transformer
1) CLIP(Contrastive Language-Image Pre-training)
OpenAI에서 개발한 인공지능 모델입니다. 이 모델은 이미지와 텍스트를 함께 학습하여 이를 활용하여 각각의 정보를 서로 연결하고, 이미지에서 텍스트를 생성하거나 텍스트에서 이미지를 생성하는 작업에 사용될 수 있습니다.
CLIP은 텍스트와 이미지 간의 유사성을 학습하는 대신, 이미지와 텍스트가 함께 있는 문장을 이해하도록 학습합니다. 이를 통해, 예를 들어 "검은 색의 개"라는 문장과 "검은 색의 고양이"라는 이미지가 어떻게 연결되는지를 학습할 수 있습니다.
이 모델은 이미지 분류, 이미지 생성, 이미지 검색, 자연어 처리, 질의응답 등 다양한 분야에서 활용될 수 있습니다. 또한, 이미지와 텍스트를 함께 고려하는 다양한 응용 프로그램을 개발하는 데 사용될 수 있습니다.
CLIP 은 약 4억개의 image, text pair data를 사용하였다. Supervised Learning 이라고 볼 수 있다.
Image Encoder 로는 Vit-B 를 사용하였고 Text Encoder로는 Transformers를 사용하였다.
Contastive Learning

Contrastive learning은 예를 들어 강아지 image가 있을 때 dog 라는 text는 embedding space 상에서 가깝게 하고, 다른 text들은 멀게 만드는 learning 을 말한다.
이 때 CLIP 에서는 cosine similaritiy loss 를 사용해서 Learning을 진행했다.


여기서 대각선 방향의 색칠 한 부분은 아까 말한 가까이 붙여야하는 것들이다. 따라서 이것들은 Cosine similiarity를 Maximize해야한다.
반대로 색칠하지 않은 것들은 Push 하여야할 것들이기 때문에 Cosine similarity를 minimize해야 한다.
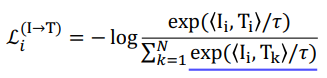
따라서 분자에 있는 term 은 maximize 하고 분모에 있는 term 은 minimize 해야한다. 그러면 전체 term 은 작아지게 되므로 전체 loss 는 작아지는 쪽으로 학습하게 된다.

이 때 Image 에서 Text로 가는 loss도 존재하지만 반대로 해석할 수 있는 loss도 존재한다. 이러한 것을 Symmetric cross-entropy loss라고 한다.
2) CLIP 응용 model
1. Image captioning - ZeroCap
ZeroCap 은 CLIP 과 large language model 인 GPT-2 를 활용한다. 이러한 ZeroCap은 새로 training을 진행하느 것이 아니라 Optimization을 통해 바로 결과를 생성해 준다.
먼저 GPT-2에 대해서 먼저 알아보자.

먼저 여기서 Context는 과거의 Key, Value 들을 말한다. 이것을 모아놓고 History 처럼 사용한다. 그리고 Captioning을 할 때는 Image of a 라는 prompt를 구성한다. 그래서 어떤 image인지 예측하는 task를 GPT-2로 활용한다.

Image 주어졌을 때 text 와 align 하기 위해 CLIP Loss를 사용한다. 즉 Image를 Image encoder에 넣고 text를 text encoder에 넣어 각 단어와 이미지의 유사도를 보는것이다.
그 후 key , value context 를 update한다. 예를 들어 bald 라는 단어가 GPT-2에 들어왔을 때 다음 단어를 예측하게 된다. 이 때 나온 단어들을 CLIP loss에 넣고 역전파를 통해 context를 update한다. 이를 5번 반복해서 update를 진행한다.
이 과정을 통해 eagle이 선정되면 이것을 다시 GPT-2에 넣어 다음단어를 예측하게 된다.
그리고 또다른 loss 로 CE loss를 사용한다. Update 된 context때문에 갑자기 결과가 튀거나 다르지 않게 조정해주는 역할을 한다.

한 이미지마다 이 loss를 통해서 optimization을 하고 이를 통해 training없이 caption 을 생성한다.
이러한 Zero-shot result 는 좋은 결과를 내놓는다. 또 OCR task도 수행할 수 있는 능력을 보여주고, visual-semantic 을 이해하는 것도 보여준다.
2. Image stylization - StyleCLIP

StyleCLIP은 CLIP + StyleGAN을 이용한다. Text를 주면 그에 따라 이미지를 수정한다.

Image가 있을 때 StyleGAN은 pretrain되어 있다. Mapping network는 specific 한 이미지에 대해서 학습되어있는 network이다. Overfitting 되어있다. 따라서 다른 이미지 사용시 다시 학습을 해야한다.
StyleGAN에 해당하는 latent vector를 먼저 준비해야한다. 그리고 Skip connection 을 이용해 원래의 속성을 유지한다. 그리고 필요한 부분만 학습한다. M 과 델타가 학습된다고 보면 된다.
먼저 CLIP Loss 를 사용해서 학습의 결과로 나온 이미지와 text사이의 loss를 minimize한다. 이미지와 text를 잘 align 시키기 위해서 그런것이다.
또 ID loss를 사용해서 original image와 출력된 이미지의 사람이 바뀌면 안되는 것을 제약해준다.
L2 loss는 너무 많은 수정으로 이미지가 바뀌지 않게 한다. 즉 수정을 최소한으로 해서 output을 내라는 의미의 loss이다.
3. video retrieval - CILP4Clip
CLIP 은 image 와 text간 align 을하기 때문에 video에 바로 적용할 수 없다. 따라서 CLIP 의 정보를 넘겨준다.

그래서 CLP model 을 large scale의 video-language dataset에 Finetuning 한다
먼저 Text Encoder 는 앞에서 봤던 것처럼 존재하게 된다. 그리고 ViT에는 기존의 이미지가 아니라 영상의 patch가 한번 가공되서 들어가게 되는데 이 때 patch 들은 t x h x w 의 size를 가지게 된다. 글고 3D linear projection 을 통해 output을 내놓게 된다. 이렇게하면 ViT의 구조는 바뀔 필요가 없다.

이렇게 해서 만들어진 Text representation 과 frame representation 이 존재하게 되는데 이의 similarity를 계산해야한다. 이미지 같은 경우는 patch들을 하나의 feature 로 표현할 수 있지만 동영상의 경우 clip 단위로 나올 수 도 있다. (t축으로) 따라서 cosine simialiraity 말고 3가지의 방법으로 실험했다.
첫 번째 방법은 Parameter free type 으로 mean pooling이다. frame들을 mean pooling 해서 하나로 만들어준 후 기존의 cosine similirarity 처럼 계산을 해준다.

2번 째 방법은 Sequential Type 으로 Transformer Encoder 나 LSTM 으로 하나의 feature를 만들어주는 방법이다. 이 부분은 학습이 필요하다.

3번 째 방법은 Tight type으로 Transformer Encoder를 통해 전체를 그냥 넣는 방법이다. 이 방법이 가장 성능이 낮았다고 한다.
4. text-to-image-Generation - DALL-E2

CLIP 과 diffusion model을 활용하였다.

pretrain 된 CLIP 을 활용한다. 마찬가지로 Image encoder의 결과와 CLIP loss를 측정한다. 그리고 text encoder에서 나온결과가 text의 visual 적인 특성을 반영한다고 생각할 수 있어 이 text로부터 이미지를 생성하는 decoder를 따로 학습한다.
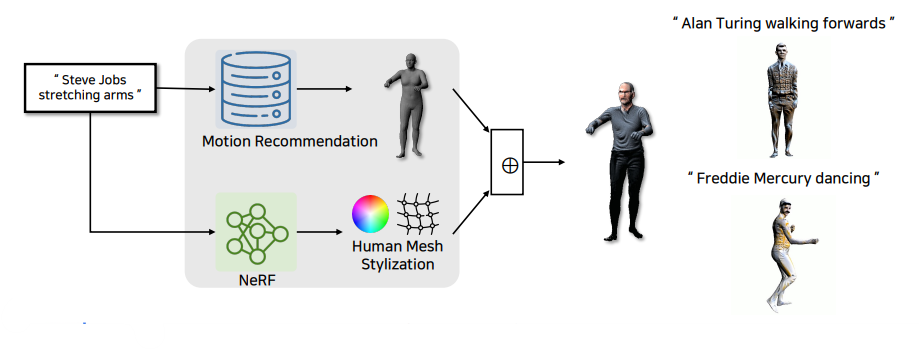
5. 4D human generation - CLIP-Actor