
Merge
erge는 둘 이상의 데이터 프레임을 하나로 병합하는 pandas 함수입니다. SQL의 JOIN 작업과 비슷한 개념으로, 두 데이터 프레임 사이의 공통된 열(Column)을 기준으로 합칩니다.
pandas에서는 merge() 함수를 사용하여 두 개 이상의 데이터프레임을 병합할 수 있습니다. merge() 함수는 다음과 같은 매개변수를 사용합니다.
- left: 왼쪽 데이터프레임
- right: 오른쪽 데이터프레임
- on: 병합 기준 열(Column) 이름
- how: 병합 방식
- suffixes: 열 이름 충돌 시 추가할 접미사
import pandas as pd
# 첫 번째 데이터프레임
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
# 두 번째 데이터프레임
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# 두 데이터프레임 병합
merged_df = pd.merge(df1, df2, on='key')
print(merged_df)위 코드에서는 첫 번째 데이터프레임(df1)과 두 번째 데이터프레임(df2)을 'key' 열을 기준으로 병합한 후, 결과 데이터프레임(merged_df)을 출력합니다. merge() 함수에서는 기본적으로 inner join을 사용하므로, 결과 데이터프레임에는 df1과 df2의 공통된 key 값인 'B'와 'D'만 포함됩니다.
key value_x value_y
0 B 2 5
1 D 4 6
Merge의 left on, right on
merge() 함수에서 on 매개변수는 병합 기준이 되는 열(Column)의 이름을 지정합니다. 이때, left_on과 right_on 매개변수를 사용하여 왼쪽 데이터프레임과 오른쪽 데이터프레임에서 서로 다른 열(Column)을 기준으로 병합할 수 있습니다.
위의 예에서는 subject_id 로 같았지만 다를 때는 left on , right on 을 설정해준다.
join 의 종류
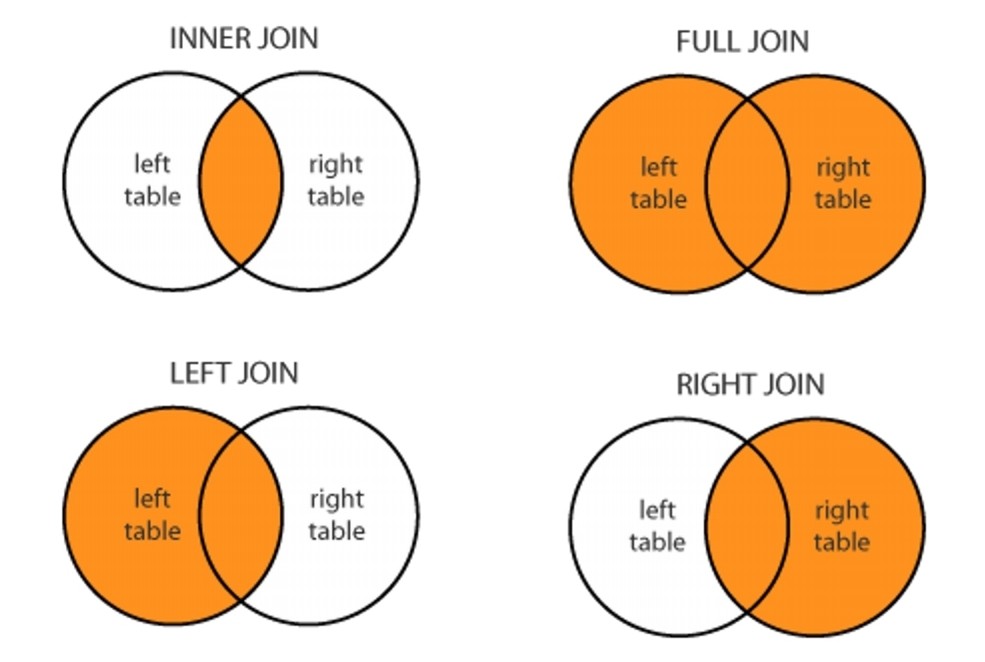
- Inner Join: 양쪽 데이터프레임에서 공통된 값만 병합합니다.
- Left Join: 왼쪽 데이터프레임의 모든 값과 오른쪽 데이터프레임에서 일치하는 값만 병합합니다.
- Right Join: 오른쪽 데이터프레임의 모든 값과 왼쪽 데이터프레임에서 일치하는 값만 병합합니다.
- Outer Join: 양쪽 데이터프레임에서 모든 값을 병합합니다. 일치하는 값이 없는 경우 NaN으로 채웁니다.
| pd.merge(df1,df2, on , how) | df1과 df2 join(on을 통해 기준열을, how로 어떤조인을 할지 지정할 수 있다.) |
| pd.merge(df1,df2,right_index=True, left_index = True) | index를 기준으로 join할 수 있다. |
Concat
| pd.concat([df1,df2]) | 기본적으로 axis = 0 (행방향)으로 붙인다. axis 설정을 통해 열방햐으로 붙일 수도 있다. |
| df1.append(df2) | 위 concat method 와 같은 의미이다.(Column수가 같다는 전제가 있다.) |
pickle persistence
Pandas에서 데이터프레임을 pickle 파일로 저장하려면 to_pickle() 메서드를 사용합니다. 이 메서드는 데이터프레임을 pickle 파일로 직렬화하고 저장합니다. 예를 들어 다음과 같은 코드를 사용하여 데이터프레임을 pickle 파일로 저장할 수 있습니다.
import pandas as pd
# 데이터프레임을 생성합니다.
data = {'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 35]}
df = pd.DataFrame(data)
# 데이터프레임을 pickle 파일로 저장합니다.
df.to_pickle('data.pkl')위 코드에서 to_pickle() 메서드는 데이터프레임을 'data.pkl' 파일로 저장합니다.
Pandas에서 pickle 파일로부터 데이터를 불러오려면 read_pickle() 함수를 사용합니다. 이 함수는 pickle 파일에서 데이터를 역직렬화하고 데이터프레임으로 반환합니다. 예를 들어 다음과 같은 코드를 사용하여 pickle 파일에서 데이터를 불러올 수 있습니다.
import pandas as pd
# pickle 파일에서 데이터를 불러옵니다.
df = pd.read_pickle('data.pkl')위 코드에서 read_pickle() 함수는 'data.pkl' 파일에서 데이터를 역직렬화하고 데이터프레임으로 반환합니다.
pickle 파일로 데이터를 저장하고 불러올 때 주의해야 할 점은 데이터가 크면 pickle 파일의 크기도 크게 될 수 있다는 점입니다. 또한 pickle 파일에 저장된 데이터는 다른 컴퓨터에서 열지 못할 수도 있습니다. 따라서 데이터를 다른 사람들과 공유해야 하는 경우에는 다른 형식으로 저장하는 것이 좋습니다.
'AI > Pandas' 카테고리의 다른 글
| Pivot table, Crosstab (1) | 2023.03.12 |
|---|---|
| Group by (0) | 2023.03.12 |
| map, replace, apply, built-in 함수들 (0) | 2023.03.12 |
| Series, Dataframe 생성, indexing, selection (0) | 2023.03.12 |