
0) Sementic Segmentation
- pixel 단위로 분류하는 것
- 기본적으로 같은 class인데 서로 다른 물체는 구분하지 않음.
1) Sementic Segmentation Architectures
AlexNet 같은 fully-connected Layer의 문제점
1. 입력이 바뀌면 fc에서의 차원이 바뀌어 호환되지 않는다. 예를 들어 만약 100 * 100의 이미지가 input으로 들어가 학습된 network가 있다면 test시 200 * 200 의 이미지가 들어간다면 fc layer에서 차원이 맞지 않게 된다.
반면 FCN은 특정해상도에서 학습되어도 test할 때는 임의의 차원의 이미지를 사용할 수 있다.
2. image의 공간정보가 저장되지 않는다. 왜냐하면 1개의 vector로 변환하기 때문이다.
반면 FCN은 공간정보가 유지된다.
1. FCN(Fully Convolutional Networks)
특징
1. semantic segmentation 에 대한 end-to-end architecture 이다.
- end - to - end: 입력에서부터 출력끝까지 미분 가능한 뉴럴넷 형태. 입력 출력만 있으면 타겟 task를 해결할 수 있다.
2. input의 image 크기와 같은 output이 나온다.

마지막 Fully convolutional layer에서는 1 x 1 convolution 을 사용한다.
1 x 1 convolution은 convolution feature map 에 있는 모든 feature vector를 분류해준다. 따라서 위의 heatmap 형식으로 output 이 나오게 된다.
하지만 이런 1 x 1 convolution 은 한계가 있다. 바로 output의 heatmap이 작게 나온다는 것이다. 왜냐하면 conv 와 pooling layer 의 를 거치면 자연스럽게 output의 크기가 줄어들기 때문이다.
따라서 이러한 heat map을 다시 키워야하는데 그것이바로 unsampling이라는 방법이다.
unsampling

위에서 pooling layer 나 stride를 넣어주어서 output 이미지가 작아진다고 했는데 그렇다면 이것을 없애면 안되냐고 물을 수 있다. 그렇다면 고해상도의 activation map을 얻을 수 있기 때문이다.
하지만 이렇게 하면 receptive filed가 작아서 context를 파악하기 힘들다. 왜냐하면 무언가를 segmentation하는 이미지의 크기가 줄어들어야 더 추상적인 특징을 뽑아낼 수 있는데 크기가 줄어들지 않으면 파악하기 힘들기 때문이다. 따라서 일단 저해상도로 작게 만들고 receptive filed를 키우는게 좋다.
그리고 이러한 receptive filed를 키우는 과정이 unsampling이다.
unsampling
1. Unpooling : 잘 사용하지 않는다.
2. Transposed convolution
3. Upsample and convolution
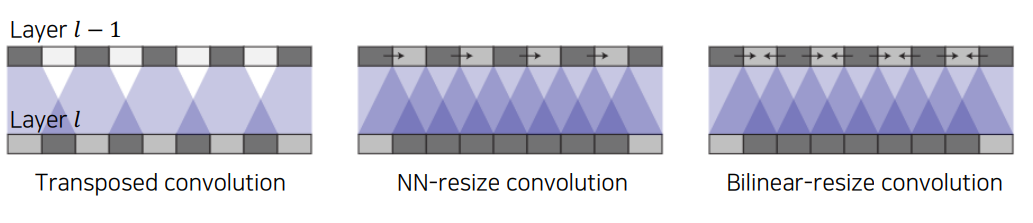
Transposed convolution 에서 주의 할점
겹치는 부분이 생겨 중첩이 생긴다. 따라서 kernel size 와 stride를 잘 조절해 중첩을 방지해야합니다. 이러한 현상을 Checkerboard artifacts라고 합니다.
그래서 이러한 문제점이 생길 수 있는 Transposed convolution 보다는 Upsampleing 과 Conv를 동시에 사용하는 것을 사용하기도 한다.
이러한 UpSampling 과정은 interpolation(Nearest-neightbor, Bilinear) 과 같은 과정으로 이루어져 있는데 이는 그냥 해상도만 키워주는 것에 불과하다. prameter가 없다는 것이다. 따라서 학습 가능한 Unsampling을 만들기 위해 conv 를 적용 시켜준다.

하지만 이러한 upsampling을 하여도 잃어버린 정보를 다시 찾는 것은 힘들다. 따라서 고해상도와 저해상도의 이미지가 둘다 필요하다. 즉 잃어버린 정보의 의미를 파악하기 위해서는 이미지 전체를 보며 판별해야한다는 이야기이다.

위에서 봤듯 저해상도 이미지와 고해상도 이미지를 fusion해야한다. pool4 를 보면 poo4와 함께 2배 unsampling해서 차원을 맞춰준 conv7 과 더해준다. 그리고 32 x 32 이미지를 맞추기 위해 다시한번 16배 unsampling을 해서 차원을 32로 맞춰준다. 이 때 conv7은 저해상도 이미지로 sementic 한 의미가 있다. 즉 강아지라면 강아지 전체를 인식하고 있는 이미지인 것이다. 반면 pool4 는 고해상도의 이미지로 강아지의 코정도를 인식하고 있는 feature map이다. 이 두가지의 feature map을 더한 후 unsampling 해주면 더 좋은 결과를 낼 수 있는 것이다.
요런 것을 skip connection 이라고 한다.

이렇게 해서 나온 결과를 보면 FCN-8이 더 선명하게 구분 지은 것을 볼 수 있다. 따라서 중간 단계의 특징을 합쳐서 쓰는 것이 더 도움이 된다는 것을 알 수 있다.
2. U-Net
Segmentation 의 breakthrough의 시작.
특징
1. FCN이다.
2. 낮은 층과 높은 층의 결합을 더 잘하는 방향을 제시하였다.
3. 정확한 segmentation 결과가 나온다.
U-Net의 구조

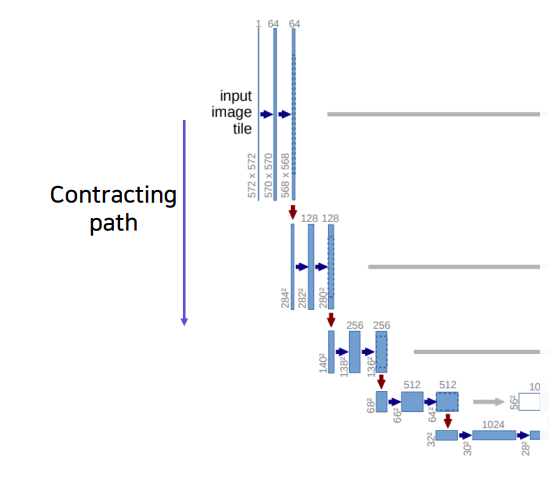
왼쪽을 Contracting Path 라고 부르고 일반적인 CNN과 동일하다.
- 3 x 3 Convolution을 반복해서 수행한다.
- 또 max-pooling할 때 feature channels 수가 2배씩 증가한다.
- 해상도를 줄이며 추상화를 진행한다.
왜 channel 수를 늘릴까??
U-Net은 입력 이미지에서 특징을 추출하는 인코더와, 추출된 특징을 이용하여 원하는 출력을 생성하는 디코더로 구성되어 있습니다. 인코더에서는 입력 이미지의 공간 정보를 추출하는 과정에서 다양한 필터를 사용하여 각 필터마다의 특징을 추출합니다. 이때, 필터의 수가 적으면 모델이 학습할 수 있는 특징의 다양성이 낮아지므로, 모델이 입력 이미지에서 의미 있는 정보를 추출하는 능력이 제한됩니다.
따라서, U-Net에서는 인코더에서 다양한 특징을 추출하기 위해 채널 수를 늘리는 방법을 사용합니다. 채널 수를 늘리면 입력 이미지에서 다양한 특징을 추출할 수 있고, 디코더에서 이를 이용하여 더 정확한 출력을 생성할 수 있게 됩니다.
또한, U-Net에서는 skip connection을 사용하여 인코더와 디코더 간의 정보 전달을 수행합니다. 이때, skip connection을 통해 전달되는 feature map의 채널 수가 일치해야 합니다. 따라서, 디코더에서 생성되는 feature map의 채널 수를 인코더에서 생성되는 feature map의 채널 수와 맞춰주기 위해 채널 수를 늘리는 작업이 수행됩니다. 이를 통해, 두 feature map을 결합하고 채널 수를 유지하면서, 공간 정보를 보존한 채로 분할 결과를 생성할 수 있게 됩니다.
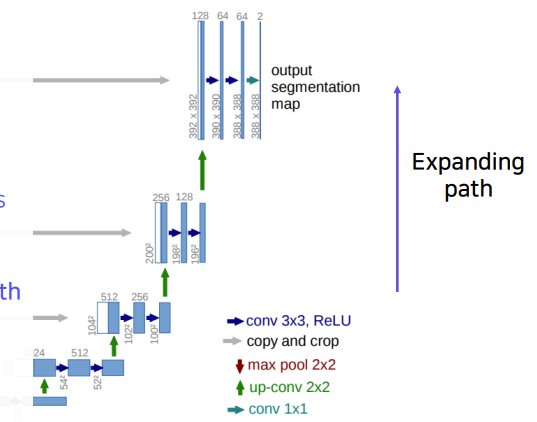
그리고 다시 channel size를 줄이고 해상도를 올리는 것을 Expanding path 라고 한다.
- 이 때 2 x 2 convolution 연산을 진행한다.
- channel 의 수는 1/2씩 줄어든다.
- 또한 contracting path에 있던 feature map을 해당하는 곳에 Concat해서 skip connection을 진행한다. 이 때 차원을 맞추기 위해 1 x 1 Conv 연산을 사용한다.
정리하면 contracting path에서는 size 가 줄고 channel은 증가하는 반면 expanding path에서는 size 가 증가하고 channel이 감소한다.
U-Net 사용시 주의점
만약 feature map의 size가 홀수 라면???
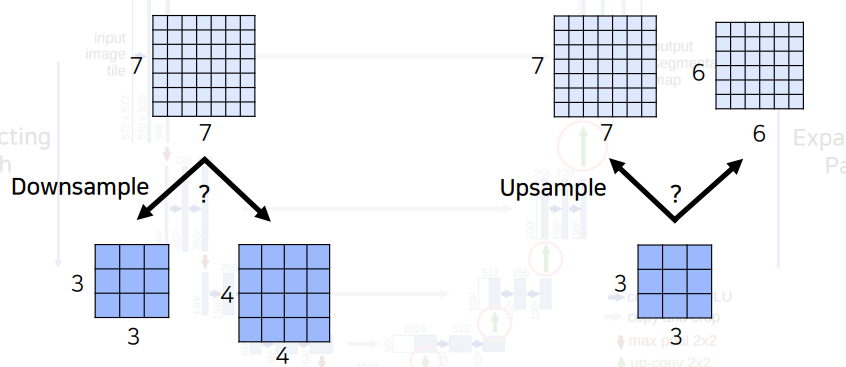
그렇다면 Downsample할 때를 보자. 7을 downsample 한다면 숫자를 버려 3의 크기의 feature map으로 downsample 한다. 하지만 이 3의 feature map을 다시 upsample 한다면 6의 feature map으로 바꿔버려 처음의 크기와 일치 하지 않게 된다.
따라서 어떤 Layer에서도 홀수해상도가 나오면 안된다.
3) DeepLab
중요한 것 2가지
1. CRFs
CRF는 이미지에 대한 통계적인 모델링 방법으로, 이미지 분할 과정에서 추출된 특징을 이용하여 객체 경계를 더욱 정확하게 추론하는 방법입니다. 이를 통해, semantic segmentation의 정확도를 높일 수 있습니다.
2. Atrous Convolution(Dilated convolution)

기존 의 Convolution 연산이 아닌 1칸 씩 띄워서 Conv 연산을 진행한다. 이를 통해 receptive field 는 커지게 하고 param 수는 변화하지 않는다. 이 때 receptive field 는 지수 증가로 확장 할 수있다.
depthwise separable convolution


보통의 Convolution 의 경우 한번에 내적을 하여 구한다.
하지만 Depthwise 는 2가지로 나눠서 진행한다.
1. 먼저 각 채널마다 내적을 구한다.
2. 그 후 각 1x 1 conv로 채널의 결과값을 한번에 모은다.
이렇게 하면 conv 의 표현력을 유지하며 계산량을 줄일 수 있다.

참고자료
'AI > CV' 카테고리의 다른 글
| Instance Panoptic Segmentation (0) | 2023.03.31 |
|---|---|
| CNN Visualization (0) | 2023.03.30 |
| Object Detection (R-CNN, YOLO, SSD, DETR, Transformer) (1) | 2023.03.29 |
| Computer Vision 개요 (0) | 2023.03.27 |
| Annotation Data Efficient Learning (0) | 2023.03.27 |